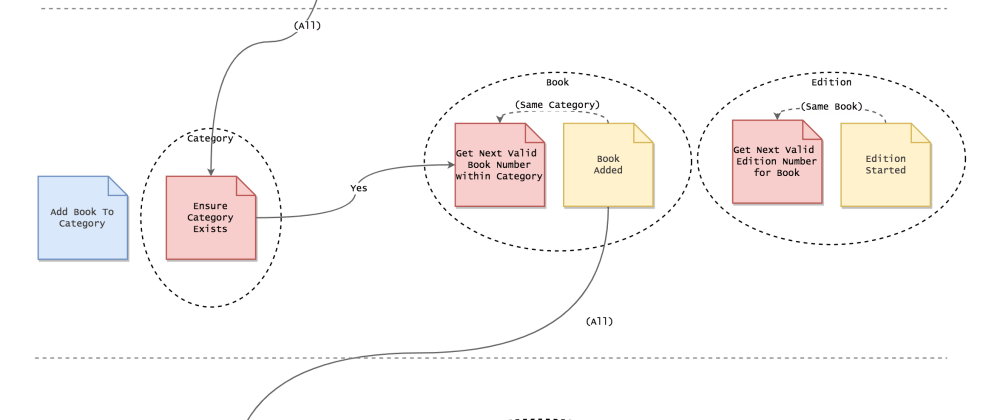
So, last time we looked at our event flow, and I went into detail about the problems we've had with it. The next step was to remodel our event flow, not as it is, but how it should be.
As part of this exploration, I also annotated the event flows, being more precise on what's needed by each iteration of the flow to ensure constraints are met. Ie. Do we need to listen to all events, or just a subset, and if it's a subset, can we define it?
The updated model

Click to zoom
What did we discover?
The above re-modelling gave us some interesting insights.
Dual events are a no go
First, our dislike of the dual events ("Book Edition Started" and "Edition Started"), was justified. The domain expert never mentioned two events, they only ever used one. It turns out we added an extra event to suit our implementation, which was a bad idea in hindsight (breaks the Dependency Inversion Principle). Wouldn't have discovered this unless we'd has this session, so that's an excellent lesson.
New constraint
That's not all though. We also discovered a constraint that we hadn't put in the last model. When you add a new book edition, you must reference the edition that you're replacing, and that edition can be any of the previous editions, not just the last one (We have a strange library). That's why there's a new constraint in the last flow, "Ensure Base Edition Exists".
New term
Another simple insight, a new word appeared, "Library". A collection of Categories belongs to a concept, but we never named it, so this word was introduced to add clarity.
And the biggest discovery is below, as it opens a can of worms.
Smaller consistency boundaries
The final discovery is around the consistency boundary for our constraints. Before we'd assumed that they needed to be globally transactional, ie. each constraint must be up-to-date with all events before another process can use it. This was not the case, the constraints we're actually a lot simpler. If you look at the model above, you'll see new annotations on top of the events required by constraints.
For example, say we're adding a book to a category, to generate a valid book number, we don't need to be update on every "Book Added" event, just the ones produced by that category. That is a much smaller consistency boundary, which makes things interesting.
Interesting?
Yep, because it's solves a major problem that we had tried to work around. Last time, we didn't explain why we added the extra event 'Book Edition Started", not really. The reason for it was to avoid the global transaction problem.
Global transaction problem
In order for our global constraints to work, they need to be up to date with every event they listen for. Only then can they generated valid numbers. This forces our processes to operate sequentially when they needed to use this resource. If too many processes hit the constraint at once and generate numbers, some of them will fail. This is guaranteed. Talk about a major bottleneck for our application. (Bottlenecks like this are a really interesting topic, will write more about it later)
That's why we explored the idea of dual events, the extra event allowed the "Book" aggregate to generate edition numbers. Our aggregates are guaranteed transactional, so it greatly reduced the size of the transactional boundary. This was a bad solution in hindsight, it added too much extra complexity, but it was going in the right direction, smaller transactional boundaries.
Solution
Our exploration above gave us the answer. We only need to ensure the constraint is up-to-date with a subset of the events, the events that reference the parent concept. Eg. If you wan't to generate a Book number, the constraint only needs to be up to date on "Booked Added" events for that particular Category, not all Categories.
I think we can implement this with database locks. In the above, we'd start a lock across the Category for the constraint when we access it. Then we'd release the lock when we store the events and update the constraint. This will force the app to be consistent, while limiting the number of failed simultaneous requests. We don't know how difficult it will be to add this to our system, so a little investigation is required.
What are our next steps?
Hope you got through all that. With all the above in my mind, what are our next steps? Well, this all depends on the problems we're solving. So let's look back at the problems we defined.
- Don't like global constraints living inside aggregates
- Inconsistent distribution of data across events
- Train of object creation is awkward
- Competing techniques to guarantee constraints
- There are redundant events
- Global constraints aren't great
Let's address these one by one, and see what our exploration above has produced as potential solutions.
1. Don't like global constraints living inside aggregates
It seems like we didn't get into this, but we kinda did. We want to remove the aggregate controlled constraint and replace it with one of it's brethren. To me it sound like we think the logic doesn't belong in the aggegrate (it doesn't), so let's double down on this and extract these constraints from within the aggregates and move them into the usecase layer.
2. Inconsistent distribution of data across events
We looked into this as well. It's clear we want to remove the unneeded event, which will force us to distribute our data in one event, rather than two. Not as hard as it sounds, we just need to write an event upgrader that merges the two events into one and update the listeners.
(we have the tools for this already, go forward thinking!).
3. Train of object creation is awkward
I think we're going to have to swallow this one for now. Our exploration didn't uncover anything related to this, and we've had no new insights, so further work into this isn't prudent. We'll just accept the complexity and re-address it when we've more information or it becomes a serious problem (it's currently a minor problem).
4. Competing techniques to guarantee constraints
We've definitely addressed this one. It's obvious that the non-aggregate controlled constraint technique is the best, so we're proposing to remove the old aggregate controlled constraint and switch over to the winning technique.
5. There are redundant events
Already addressed above.
6. Global constraints aren't great
We're also really delved into this problem. Turns out the global constraint is too strict, and by shrinking it, we can reduce the likelihood of failed processes by an order of magnitude. There is a bit of work in this, so I suggest we put monitoring into our current app to measure how likely these failures are, this will tell us how quickly we'll need to address this issue.
Conclusion
I think its clear from the above that a revisit to the domain model paid of massive dividends. We got some great insights into the problems we're having, and we've got the beginnings of their solutions. From this we can move onto the next step, turn the above into an actionable plan and incorporate that into our workload.
Which is what I'm going to write about next, hope you enjoyed.


















