
Have you ever felt overwhelmed by the sheer volume of information contained in documents, desperately searching for that one crucial piece of data? Well, my friend, your search is over. Today, we're going to learn how to use Langchain to answer questions from documents effortlessly. This revolutionizes the way you access and understand information!
In this guide, I'll explore LLMs, embeddings, and vector stores. I'll dive deep into the nitty-gritty of code, examples, and real-world applications, covering 7 key points.
1. The Groundwork: Setting Up Your Environment
Before we can unleash the true power of LLMs, we need to lay the foundation. In this section, we'll cover the essential steps to set up our environment, import the necessary libraries, and load the data we'll be working with.
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import CSVLoader
from langchain.vectorstores import DocArrayInMemorySearch
from IPython.display import display, Markdown
from langchain.llms import OpenAI

2. The Vector Store Index: Your Personal Information Concierge
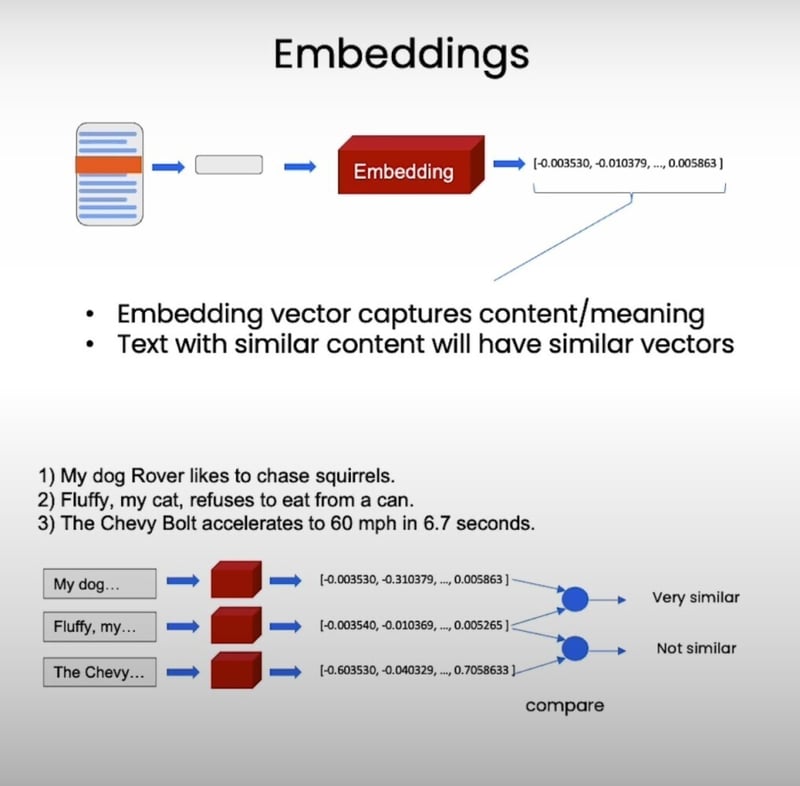
At the heart of our question-answering system lies the vector store index. Think of it as your personal information concierge, ready to fetch the most relevant documents at your beck and call. But how does it work, you ask? Well, let me tell you a little story...
Imagine you have a massive library filled with books on every topic imaginable. Now, instead of randomly searching through each book, you create a unique code (or embedding) for each book based on its content. These embeddings act like a secret language, enabling you to quickly identify books with similar themes or topics. Pretty nifty, right?
But wait, there's more! You then store these embeddings in a vector store, which acts as a highly organized database. When you need to find information on a specific topic, you simply provide a query, and the vector store retrieves the most relevant books based on their embeddings. It's like having a personal librarian who understands your needs better than you do!
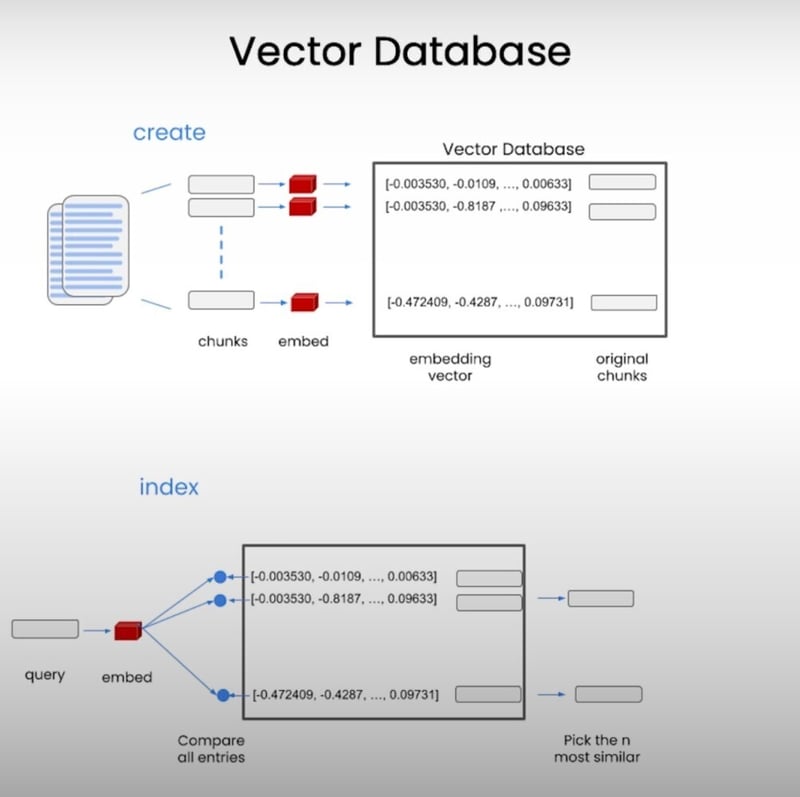
3. Creating the Vector Store Index
Now that you understand the magic behind vector stores, it's time to create our own. We'll be using the VectorstoreIndexCreator to make this process a breeze.
file = 'OutdoorClothingCatalog_1000.csv'
loader = CSVLoader(file_path=file)
from langchain.indexes import VectorstoreIndexCreator
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch
).from_loaders([loader])
In our example, we're loading a CSV file containing information about outdoor clothing. We then create a vector store index using the VectorstoreIndexCreator and specify the type of vector store we want to use (DocArrayInMemorySearch). This index will be most important part of Langchain question answering.
4. Querying the Index: Ask and You Shall Receive
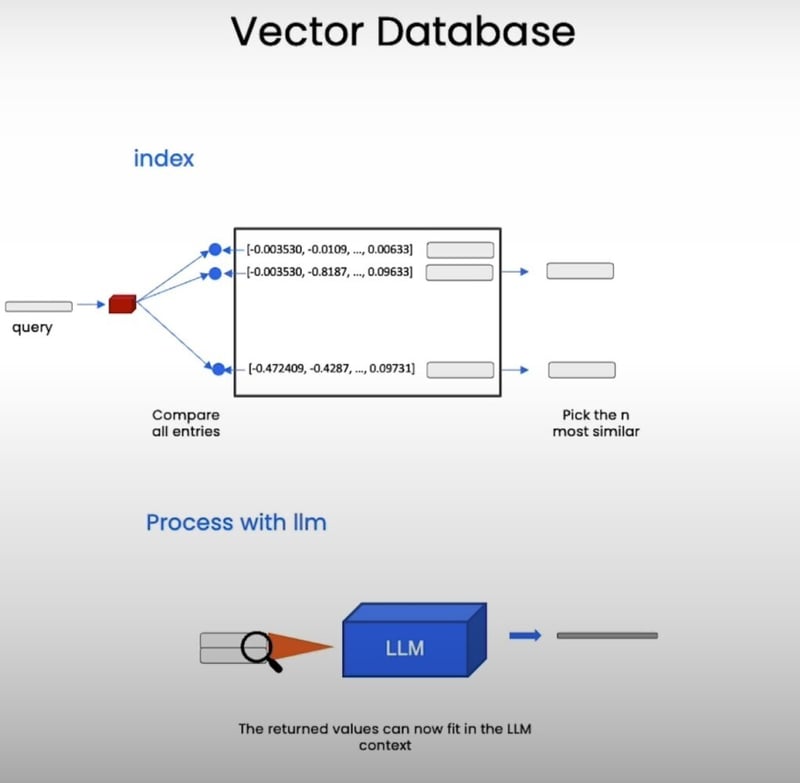
With our index set up, we can now put it to the test. Let's say we want to find all the shirts in our catalog that offer sun protection. We can simply ask our index:

And just like that, our index returns a beautifully formatted table with all the relevant shirts and their descriptions. It's like having a personal shopping assistant who understands your needs better than you do!
5. Under the Hood: A Step-by-Step Breakdown
But what if you want to take a closer look at the inner workings of this process? No problem! We can break it down step-by-step:
from langchain.document_loaders import CSVLoader
loader = CSVLoader(file_path=file)
docs = loader.load()
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
db = DocArrayInMemorySearch.from_documents(docs, embeddings)
query = "Please suggest a shirt with sunblocking"
docs = db.similarity_search(query)
retriever = db.as_retriever()
llm = ChatOpenAI(temperature=0.0, model=llm_model)
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
response = llm.call_as_llm(f"{qdocs} Question: {query}")
display(Markdown(response))
First, we load the documents from the CSV file and create embeddings for each document using OpenAI's embedding model. These embeddings are then stored in our vector store (DocArrayInMemorySearch). When we provide a query, the vector store performs a similarity search and retrieves the most relevant documents based on their embeddings.
Next, we create a retriever from the vector store and initialize a language model (ChatOpenAI). We combine the retrieved documents into a single string and pass it, along with our query, to the language model. The language model then generates a response, which we display in a formatted manner using Markdown.
It's like having a team of experts working behind the scenes to provide you with the information you need, when you need it.
6. Customization and Advanced Options
The beauty of LangChain lies in its flexibility and customization options. We can swap out the vector store class, embeddings, and even the language model to suit our specific needs.
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=embeddings,
).from_loaders([loader])
For example, in the code snippet above, we're specifying a custom embedding model to be used for creating the vector store index. This gives us more control over how the embeddings are generated, which can impact the quality of our search results.
7. Different Question Answering Methods

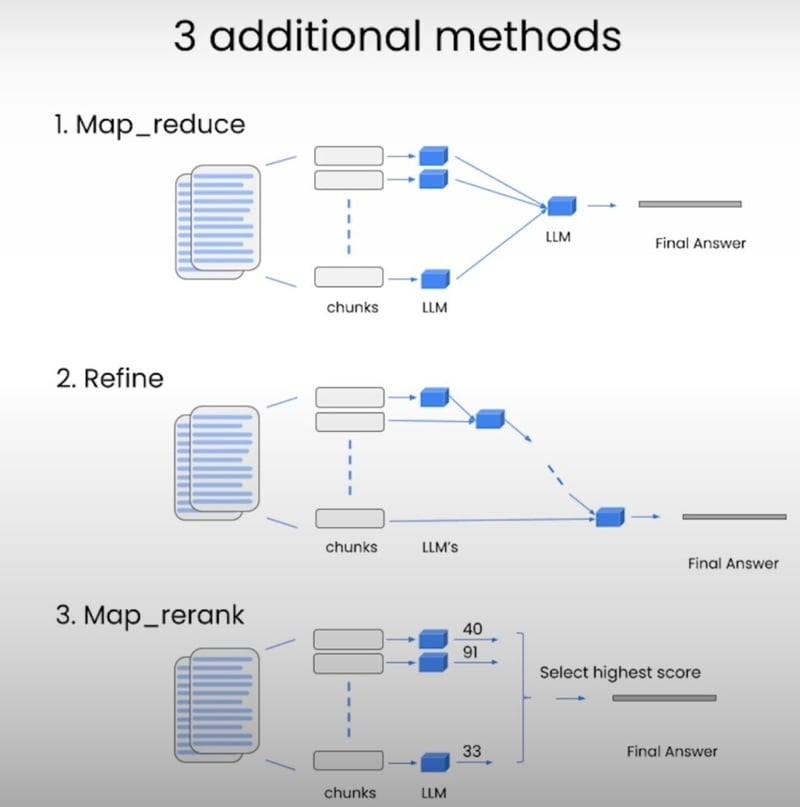
While we've focused on the "stuff" method in this blog, LangChain offers several other methods for question answering, each with its own pros and cons. Let's briefly explore them:
Map Reduce: This method takes all the chunks, passes them along with the question to a language model, gets back a response, and then uses another language model call to summarize all the individual responses into a final answer. It's useful because it can operate over any number of documents, and the individual calls can be parallelized for speed.
Refine: Similar to Map Reduce, this method loops over many documents iteratively, building upon the answer from the previous document. It's great for combining information and building up an answer over time, but it's slower because the calls are not independent.
Map Rerank: In this experimental method, you do a single call to the language model for each document, and you also ask it to return a score. You then select the highest-scored response. This relies on the language model's ability to score the relevance of its own output, which can be tricky to configure.
While the "stuff" method is the simplest and most commonly used, these alternative methods offer different trade-offs in terms of speed, cost, and answer quality, depending on your specific use case.
Conclusion:
By now, you should have a solid understanding of how LLMs, embeddings, and vector stores can revolutionize the way you access and understand information. But this is just the tip of the iceberg, my friend. The possibilities are endless, and the journey has just begun.
Imagine being able to ask questions about your company's internal documents, legal contracts, or even scientific research papers, and receiving concise, relevant answers in seconds. With LLMs, you can unlock a world of knowledge that was once hidden behind mountains of text.


















