
Photo by SELİM ARDA ERYILMAZ on Unsplash
The rise in self-service analytics is a significant selling point for data warehousing, automatic data integrations, and drag and drop dashboards. In fact, in 2020, the largest software IPO this year was a data warehousing company called Snowflake.
The question is how do you get your data from external application data sources into a data warehouse like Snowflake?
The answer is ETLs and ELTs.
ETLs (Extract, Transform, Load) are far from new but they remain a vital aspect of Business Intelligence (BI). With ETLs, data from different sources can be grouped into a single place for analytics programs to act on and realize key business insights.
ELTs have the same exact steps referenced by ETLs except in a slightly different order. In particular, the major difference lies in when the transform step occurs. We will discuss in depth what the T stands for shortly. However, to talk about it abstractly, it references business logic, data pivoting and transformations that often take a lot of time and resources to maintain.
In addition to covering what the E, L, and T stand for, this article will also cover the ETL process and various tools.
What is an ETL(Extract, Transform, Load)?
Data is the foundation of the modern business world. Data on its own is not very useful. On top of that, the data is often stored in some form of application database that isn't easy to use for analytics.
This is why ETL tools are essential. ETLs take data from multiple systems and combine them into a single database (often referred to as a data warehouse) for analytics or storage.
ETLs imply data migrating from one application/database to an analytical database. An ETL takes three steps to get the data from database A to database B. These are:
Extract (E)
Transform (T)
Load (L)
Extract
The extract function involves the process of scraping and or extracting data from a database, API, or raw website.
Transform
The transform function converts the extracted data into a proper format for analysis and storage. This process includes changing the extracted data from its old structure into a more denormalized format. This step is dependent on the end-database. For example, data warehouses have a very specific design pattern that requires reshaping data and implementing slowly changing dimensions.
Load
The load function takes the process of writing the transformed data into the new application/database. This could take several steps as each stage might augment the data differently. The standard setup is to have raw, staging, and production databases. There are other configurations depending on the project's needs.
Why Are ETLs Important?
Regardless of the company size, the level of complexity, and the number of data sources, companies will always benefit from better access to their data. ETLs provide access to what's happening in their processes. They also provide the ability to create reports and metrics that can drive strategy.
These reports and metrics are a crucial part of competing with other similar organizations.
So the next question is: which type of ETL tool should your company pick?
Now That You Know What An ETL Is --- What Tool Should You Use?
Before we talk about designing an ETL. We should look through the options your team has for building an ETL. There are dozens upon dozens of options of ETL tools your team could use to develop your data pipelines. Below are some common ETL options as well as some newer tools that are trying to vie for market share.
ETL Tools

Airflow
Airflow is a workflow scheduler that supports both task definitions and dependencies in Python.
It was written by Airbnb in 2014 to execute, schedule, and distribute tasks across several worker nodes. Made open source in 2016, Airflow not only supports calendar scheduling but is also equipped with a clean web dashboard which allows user to view current and past task states.
Using what it calls operators, your team can utilize python while benefiting from the Airflow framework.
For example, you can create a Python function and then call it with the PythonOperator and quickly set what operator depends on to run before, when it should run and several other parameters.
In addition, all of the logging and tracking is already taken care of by Airflows infrastructure.
Luigi
Luigi is an execution framework that allows you to write data pipelines in Python.
This workflow engine supports task dependencies and includes a central scheduler that provides a detailed library for helpers to build data pipes in MySQL, AWS, and Hadoop. Not only is it easy to depend on the tasks defined in its repos, but it's also very convenient for code reuse; you can easily fork execution paths and use the output of one task as the input of the second task.
This framework was written by Spotify and became open source in 2012. Many popular companies such as Stripe, Foursquare, and Asana use the Luigi workflow engine.
SSIS
SSIS or SQL Server Integration Services is Microsoft's workflow automation tool. It was developed to allow developers to make automation easy. SSIS does so by providing developers with drag and drop tasks and data transformations that just require a few parameters to be filled out. Also, SSIS's GUI makes it very easy to see which tasks depend on what.
Because SSIS only allows for a limited number of data transformations, SSIS also offers a custom code transformation so data engineers aren't limited to the basic transforms SSIS offers.
Talend
Talend is an ETL that has a similar feel to tools like SSIS. It has drag and drop blocks that you can easily select use for destinations, sources, and transformations. It connects to various data sources and can even help manage and integrate real-time data like Kafka.
Talend's boast and or claim to fame is it is 7x faster and ⅕ the cost. However, when it comes down to it, most products will state something similar. It can take a little bit of fine-tuning to get that optimal performance. At the end of the day, your performance is connected more to who builds your pipelines and who designs your data warehouses vs the product you use.
Fivetran
Fivetran is a highly comprehensive ELT tool that is becoming more popular every day. Fivetran allows efficient collection of customer data from related applications, websites, and servers. The data collected is then transferred to other tools for analytics, marketing, and warehousing purposes.
Not only that, Fivetran has plenty of functionality. It has your typical source to destination connectors and it allows for both pushing and pulling of data. The pull connectors will pull from data sources in a variety of methods including ODBC, JDBC, and multiple API methods.
Fivetran's push connectors receive data that a source sends, or pushes, to them. In push connectors, such as Webhooks or Snowplow, source systems send data to Fivetran as events.
Most importantly Fivetran allows for different types of data transformations. Putting the T in ELT. They also allow for both scheduled and triggered transformations. Depending on the transformations you use, there is also other features like version control, email notification, and data validations.
Stitch
Stitch was developed to take a lot of the complexity out of ETLs. One of the ways Stitch does this is by removing the need for data engineers to create pipelines that connect to APIs like in Salesforce and Zendesk.
It also attaches to a lot of databases as well like MySQL. But it's not just the broad set of API connectors that makes Stitch easy to use.
Stitch also removes a lot of the heavy lifting as far as setting up cron jobs for when the task should run as well as manages a lot of logging and monitoring. ETL frameworks like Airflow do offer some similar features. However, these features are much less straightforward in tools like Airflow and Luigi.
Stitch is done nearly entirely in a GUI. This can make this a more approachable option for non-data engineers. It does allow you to add rules and set times when your ETLs will run.
Airbyte
Airbyte is a new open-source (MIT) EL+T platform that started in July 2020. It has a fast-growing community and it distinguishes itself by several significant choices:
Airbyte's connectors are usable out of the box through a UI and an API, with monitoring, scheduling, and orchestration. Their ambition is to support 50+ connectors by EOY 2020. These connectors run as Docker containers so they can be built in the language of your choice. Airbyte components are also modular and you can decide to use subsets of the features to better fit in your data infrastructure (e.g., orchestration with Airflow or K8s or Airbyte's...)
Similar to Fivetran, Airbyte integrates with DBT for the transformation piece, hence the EL+T. While contrary to Singer, Airbyte uses one single open-source repo to standardize and consolidate all developments from the community, leading to higher quality connectors. They built a compatibility layer with Singer so that Singer taps can run within Airbyte.
Airbyte's goal is to commoditize ELT, by addressing the long tail of integrations. They aim to support 500+ connectors by the end of 2021 with the help of its community.
ETL General Design
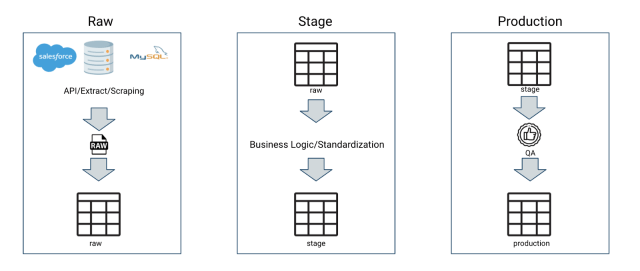
When developing a more classic ETL, there are usually several standard layers as far as tables and transforms go.
Typically there is a raw, staging and production set of tables, each playing a different role as far as what occurs in each layer.
So what happens at each of these stages?
Let's break it down.
Raw
In the raw layer, you are typically just inserting the data you extracted as is. This is to say, without any forms of data transformations.
The reason for this is because if something is wrong with the data, it is easier to tell where something went wrong. If you have a lot of complicated data transformations or missing data, it might be difficult to assess if the data is wrong in the application, the extraction, or the insertion. This is why in most cases, limiting the logic put into the insertion of raw data is beneficial. It helps reduce the amount of confusing in the future.
Staging
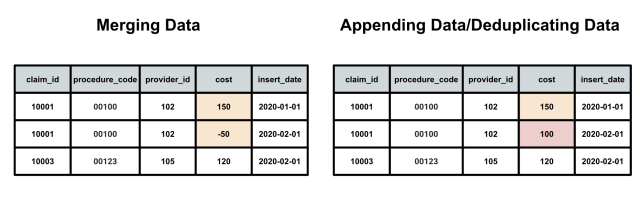
In the staging phase, this is where you will often start applying some more logic. You may start deduplicating data, standardizing it, and remodeling it.
One example of logic your team will need to consider is if the transactions occurring in the fact tables need to be deduplicated or merged together. This is dependent on how the system where the data came from treated the data.
Sometimes applications update data so the row is always accurate, other times they might require you to merge the data and of course there are still other ways an application could manage data. Thus it is important to replicate that logic in your stage layer to represent accurate data.
In addition to managing appending and deduplicating you might also need to manage what are called slowly changing dimensions. This is usually columns that change in a value slowly like where an employee works or someone's address.
To give a high level of what occurs in slowly changing dimensions. First your team needs to decide what type of slowly changing dimension to use. There are actually quite a few.

A common method is to just capture the start and end date of when some piece of information was true and leave the end date null until there is a change in data. This is depicted in the image above where the store manager changes between January and February.
One final point. Much of the appending, deduplicating and logic happens in the staging layer. However, this isn't to say none happens in production. Depending on how your data is set up, the staging layer may only manage the current data you're about to insert and not production data.
So some systems will implement this logic in production. The key is to try to put it as much in a single layer as possible so you can have an easier time maintaining the logic.
Production
The production phase can depend a little bit on the system you are using. For example, if you are using a read and insert only system. This can change how your system interacts as far as whether the system deletes everything and reloads every time or you just append.
This can also depend on how much data your team manages.
One key step that shouldn't change is QA. You have just heavily manipulated your data. It is a good idea, prior to loading into production, that your team QAs your data.
If your data fails the QA, then you need to decide whether the data checks are worth not inserting the data or not. The production layer is where analysts and data scientists will be using the data for insights.
Having wrong data in this layer, even for a short period of time risks those teams pulling the data into their own environments and providing bad results.
So it is key that the data is as accurate as possible at this step.
What Else To Consider When Designing An ETL
Just getting the data from point A to point B is not sufficient. In order to ensure your ETL system is easy to maintain and debug your team will also need to consider the following:
Error Handling And Logging Infrastructure
Data QA Infrastructure
Error Handling And Logging
Error handling is an important aspect of ETL development. Especially as systems rely more on components that are serverless, cloud based and distributed. These add lots of new complexity and fail points.
Developers will need logging and error handling that makes it easy to spot where an ETL may have failed. These logging systems are often displayed as dashboards like that of Airflow. This allows users to quickly assess which jobs have failed and which haven't.
In addition, there will often be logs that developers can track and dig into to figure out why a job may have failed. The issue might be transient and sometimes in order to fix it all a developer needs to do is restart the job. Of course, other times, bad data or a new bug may have stalled the code. The logs will help the developer figure out what is the root cause of the problem.
This logging an error systems must also avoid being too noisy in terms of notifications or emails because that can lead to developers eventually ignoring or becoming indifferent due to overwhelming benign notifications.
Data QA Infrastructure
Data QA is far from sexy. But ask any data engineer and they will tell you, garbage in and garbage out.
The notion of this statement is that building a any form of model on bad data is pointless.
One of the key steps in the ETL process is data QA. There are lots of different ways to QA your data.
For example here are several categories of data quality checks you might want to run.
Anomaly data checks
Category data checks
Aggregate checks
Null checks
These checks are all data quality checks and not unit tests which would be more specifically used for when you start developing complex logics where you expect a certain output. In this case you're just checking to make sure the data make sense.
Some third party tools even have these checks as options to run as part of their ETLs.
Anomaly checks
Anomaly checks test to make sure data makes sense. For example, let's say your company usually only experiences costs of $10-$1000 and then suddenly there is a $100,000 charge. An anomaly check would flag this as possibly incorrect. Not in terms from an operations side, but in terms of analytics.
There are similar anomaly checks for row counts that can also be used. For example, perhaps every day your system only has about 1000 rows added, and then one day you suddenly have 40,000 rows added. Hopefully this is because your application is gaining traction, but what if it isn't'.
What if there is a component that has gone wrong on the application side? That is what an anomaly check is for in an ETL.
Category Checks
Sometimes you only expect specific values to exist in your data. For example, if your data set is based on US data then there are only 50 states and a few valid territories. That means you should set a basic check that validates that only actual states or territory abbreviations exist.
This sounds strange, but I have seen the abbreviation "WE" before.
Truthfully, this check should be done in the application layer before the data is inserted. However, there are places your team may need to consider where even categorical data should be limited could go wrong.
Aggregate Checks
There is a lot of slicing, transforming and removing of data that goes on between raw to production. However, between raw and production the total amount of people, customers and or patients should remain the same. As should the total spend.
Aggregate checks make sure that the totals stay the same from start to finish.
With all the applied logic, there is a lot of risk that an accidental left join or bad bit of logic removes data. To ensure this doesn't happen your team should implement aggregate checks.
It's a great sanity check and can really help ensure that your logic isn't incorrect.
Null Checks
Null data is sometimes unavoidable. However, each row usually has a unique tolerance to how much of the data can be null. A simple way to look at this is a field like a primary key can never be null but optional fields in a form could have a wide range of of null rates (which in itself can provide a lot of value).
The point being there is usually a normal rate of nullness.
In fact, the null checks can be set up dynamically by combining them with your anomaly checks. There might be a normal rate of null values for specific columns. Instead manually coding it, your team can dynamically set this up.
In Conclusion
Today's corporations demand easy and quick access to data. This has lead to an increasing demand for transforming data into self-serviceable systems.
ETLs play a vital part in that system. They ensure analysts and data scientists have access to data from multiple application systems. This makes a huge difference and lets companies gain new insights.
There are tons of options as far as tools go, and if you're just starting to plan how your team will go forward with you BI and data warehouse infrastructure you should take some time to figure out which tools are best for you.
What you pick will have a lasting impact on who you hire and how easy your system is to maintain. Thus, take your time and make sure you understand the pros and cons of the tools you pick.
From there, you can start designing based on your businesses needs.
If you are interested in reading more about data science or data engineering, then read the articles below.
How To Use AWS Comprehend For NLP As A Service
4 SQL Tips For Data Scientists
What Are The Benefits Of Cloud Data Warehousing And Why You Should Migrate
5 Great Libraries To Manage Big Data With Python


















