
What we're up to
The web is huge, and it's getting bigger. Every. Single. Minute.
More people. Doing more things. Using more devices. On faster connections.
Everything indicates that load pressure over all kinds of applications is only up to increase: from small to big ones, from B2C through B2B. More companies will need teams that can deliver on the scalability promise.
Likely, only a handful out of every 100 developers nowadays is really into building things that can scale. You can be at the top of the market.
First Steps
A scalable system is one that can continue to perform in a reliable manner under highly variable and often increasing levels of load.
A system's scalability problem is rarely a single variable analysis. It usually involves at least two-dimensional thinking: a load metric and a time-period. More often than not, it's a multi-dimensional beast.
Some two-dimension problem examples are:
- How does the database system scales when IOPS1 increases from 1,000 to 10,000 over one second?
- How load time is affected when website pageview requests grow from 200 to 5,000 over one minute?
Bear with me along the next lines to understand the multi-dimension ones.

Load Profile
What we first need is to express what load means for each of our systems.
For a website, load can be online visitors or pageviews per second. For a database, it could be concurrent queries, the number of I/O operations, or the amount of data getting in and out.
How load is described also depends on the system architecture and the business case. This is where things start to get complicated.
In an e-commerce website, for example, the system may scale well to serve 10,000 people shopping at the same time across a thousand-item catalog. But what happens if a huge group is shopping for a single item?
Perhaps a very positive review by popular social-influencer just went viral on social networks.
We don't wanna be the ones explaining why the hot moment was missed due to system restrictions.
When scalability collides with consistency

Take a scalable database system. It will employ some sort of multi-node replication. Think of it as the product description, price, etc. replicated across different servers to handle a huge amount of read requests.
If each server can manage 1,000 RPS (req. per sec.) and we need to handle 10,000 RPS, we'll need at least 10 of those servers. The same data will be replicated in all of them. One will act as the main server to receive updates or delete requests. Once a data point is modified, the main server will notify the other servers to follow along with the update.
This is usually called a Master-Slave replication system2 and is very common in database setups.
Think about consistency now. You know "over-booking" in airline seats? That's sort of a consistency issue. Airlines do it consciously. But we don't want two shoppers ordering the same physical item, because the store won't be able to fulfill both orders.
When a purchase is confirmed, the system will decrement the number of items available in stock. And here comes the problem: the DB might be able to handle decrementing hundreds of different items at once. But what happens if thousands try to decrement the same value in a very short period?
This is the sort of circumstance that happens due to market trends and human behavior. Developers must account for these factors when thinking about load and scalability.

Handling Load
The more we strive to anticipate possible challenging load scenarios for the system, the better it will perform in reality.
It is necessary to consider:
- The load profiles and metrics
- How much and how fast load can vary
- Which resources are needed to cope with these variations without hurting performance or reliability
Thinking about load profile
Let's dive deeper into the e-commerce example.
Say the shopping cart module is responsible for checking an item's availability before confirming a purchase. A naive approach is to read the number of items available in the product's profile stored in the database and decrement it right after confirming its availability.
That strategy can lead to bottlenecks and crash under increasing loads because all order requests will be rushing to decrement the same value consistently. Not only the master node but all replicas must be updated at the same time to ensure consistency.

Better approaches
One solution would be using Multi-Master3 replication. This type of system provides the logic to handle concurrent requests. It is usually not trivial to implement, though.
Some database services will provide multi-master out of the box. This is the case of the serverless DynamoDB service, by AWS.
Using this type of service can save a lot of time. Instead of solving the infrastructure cluster and low-level replication issues, we can focus on the scalability issues specific to the user problem at hand.
Another possibility is using a message queue as a buffer, instead of having the shopping cart rushing directly to the database. All the ordered items are placed into a queue. A background job is responsible for pulling orders from the queue and processing them (check availability, decrement stock, etc).
Once all items from an order are processed, another background job can confirm the customer's purchase.
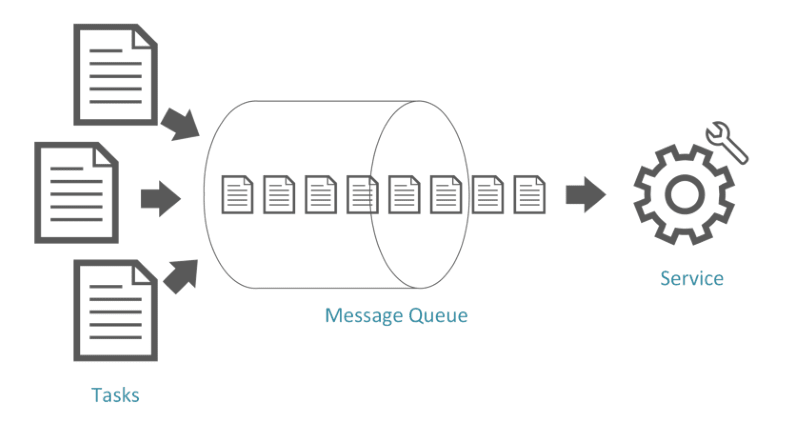
The queue buffer decouples the front and backend systems from the database and allows each to scale separately. It makes tackling scalability challenges much easier. Even when using a Multi-Master database, the message buffer is usually a good architectural pattern to consider.
How load is profiled and scalability challenges are tackled will depend a lot on the use case. There is no one-size-fits-all strategy here.
And here is where you can differentiate yourself in your software career. For many companies (not only larger but especially startups that need to grow fast), it is a must-have for the DEV team to think about scalability, anticipate challenges and build a resilient and scalable system.
Learn how to scale systems, and you can change your career. At the end of this article, there is an indication of a great book, in case you'd like to dive deeper. It's not easy and you can never study the topic too much.
Thinking about resources
Resources can scale:
- Vertically (scale-up): increasing CPU power or RAM, for example
- Horizontally (scale-out): adding more servers to a cluster, for instance

A great number of healthy architectures will mix both approaches. Sometimes, having many small servers is cheaper than a few high-end machines, especially for highly variable loads. Large machines can lead to increased over-provisioning and wasted idle resources.
When load scales down, it's much easier to kill a couple of idle small machines than to frequently move a system from big to smaller machines.
In other cases, perhaps a big machine would perform faster and cheaper than a cluster of small ones.
It depends on the case and developers must try different approaches to find one that suits both performance requirements and project budget.
Using serverless systems greatly simplifies the level of responsibility developers have over how systems cope with load. These services abstract away decision-making about scaling-up or out, for example, and also provide SLAs that the development team can rely on.

As mentioned above, one great database service is AWS DynamoDB. It solves the lower level scalability and availability issues out of the box.
For small and mid-sized teams, projects that need short time-to-market and fast iterations, using services like DynamoDB can be a great competitive advantage. It allows us to abstract away undifferentiated infrastructure issues to focus on the scalability challenges of the business case at hand.
Mastering these types of services is also a great knowledge acquisition in a developer's scalability belt. Check this Knowledge Base to learn more about scalable databases, compute engines and more.
Load Metrics and Statistics
Metrics will need some sort of aggregation or statistical representation. Average (arithmetical mean) is usually a bad way to represent metrics because it can be misleading. It doesn't tell how many users experienced that level of performance. In reality, no user might have experienced it at all.
Consider the following application load and user base:
| User | Response time |
|---|---|
| A | 210 ms |
| B | 250 ms |
| C | 240 ms |
| D | 20 ms |
The average response time would be 180 milliseconds. But no user experienced that response time. 75% of the users experienced a performance that is worse than average. The arithmetic mean is highly sensitive to outliers, which is the case of the distribution above.
This is why percentiles are more commonly used to express systems performance. They are also the basis for service level objectives (SLOs)4 and agreements (SLAs)5.
The most common percentiles are 95th, 99th, and 99.9th (also referred to as p95, p99, and p999).
A p95 level is a threshold in which at least 95% of the response times fall below. In the example above, our p95 would be 250 ms. Since we have only a handful of request samples, it would be the same threshold for all percentiles. If we were to compute a p75, it would be 240 ms, meaning: three out of four (75%) of the requests were served within 240 milliseconds.
Wrapping up
Thinking about a system load and preparing it to scale smoothly under different load profiles is no easy task. That is precisely why you should get better at it.
Gone are the times when only a handful of applications on the web needed to worry about scale. The web is already huge, and it's getting bigger.
More and more people are joining it every day. With more devices: laptops, smartphones, tablets, smartwatches, smart glasses, smart rings... Who knows what else they'll smart'ify next!?
IoT devices are exploding. Networks are only getting faster.
As I said in the beginning: everything indicates that load pressure over all kinds of applications is only up to increase. More and more companies will need teams that can provide scalable systems.
You can be one of the few, top 1% of the market delivering it.
Subscribe to our Knowledge Base and receive notifications when we publish content similar to this one.
Acknowledgements and Footnotes
This article was heavily inspired by the Designing Data-Intensive Aplications book, by Martin Kleppmann. I strongly recommend the read if you are interested in getting deeper into the topic.
- Cover Image by Katee Lue on Unsplash
- Holding plants image by Daniel Hjalmarsson on Unsplash
- Hands with elastic image by NeONBRAND on Unsplash
- Woman stretching image by Andrés Gómez on Unsplash
- Metrics dashboard image by Luke Chesser on Unsplash
- Bull collision image by Uriel Soberanes on Unsplash
- Vertical vs. Horizontal scaling image by AccionLabs
- Message queue buffer image by Christopher Demicoli
- Serverless architecture image by Ritchie Vink



















{kind=link}
{kind=link}
{kind=link}