
Welcome to the final installment of our Complete AWS Lambda Handbook series!
Given Lambda is often the central point for many serverless applications, we wanted to make sure we didn't skip or breeze past any part. In this episode, we're looking at some limitations and difficulties using AWS Lambda and how to overcome them, and the importance of monitoring for performance and failure remediation.
AWS Lambda Deployment Limitations
As great as AWS Lambda is, it's still technology at the end of the day so there will be some limitations.
Runtime Environment limitations:
The disk space (ephemeral) is limited to 512 MB.
The default deployment package size is 50 MB.
Memory range is from 128 to 3008 MB.
Maximum execution timeout for a function is 15 minutes.
Requests limitations by Lambda:
Request and response (synchronous calls) body payload size can be up to to 6 MB.
Event request (asynchronous calls) body can be up to 128 KB.
The reason for defining the limit of a 50MB deployment package is so users aren't able to directly upload one to AWS Lambda with a greater size. Technically however, the limit can be much higher if you let your Lambda function pull the deployment package from S3.
AWS S3 allows for deploying function code with substantially higher deployment package limits and in fact, most of the AWS service default limits can be raised by AWS Service Limits support request. Still it's often a case of uncertainty for many developers as to what the actual limit is, so, to find an answer, we are going to run a test by uploading deployment packages of different sizes.
AWS Lambda Deployment Package Testing
We'll be working with a Machine Learning model as our deployment package, creating random data of a specified size to test the limit of varying sizes. We'll test the following limits as described in the documentation:
50 MB: Maximum deployment package size
250 MB: Size of code/dependencies that you can zip into a deployment package (uncompressed .zip/.jar size)
For this test, we'll be using an image recognition deep learning model based on the TensorFlow Inception-v3 model. The overall file size is about 150MB, which is beyond the specified limit of 50MB.
Test One: Can You Upload A Package over 50MB?
Let's test it by directly uploading to the Lambda function. Here are the main steps we took:
- Zip package. This zip package will contain all our files such as:
classify_image.py
classify_image_graph_def.pb
MachineLearning-Bundle.zip
NB: This model was created specifically for this project. However, Machine Learning models can be downloaded from the following sources:
Keras: https://github.com/fchollet/deep-learning-models
TensorFlow: official release, performance models, tensornets
- Name package MachineLearning.zip.
zip MachineLearning.zip MachineLearning
- Check if the file can be compressed.
$ ls -lhtr | grep zip
-rw-r--r-- 1 john staff 123M Nov 4 13:05 MachineLearning.zip
Even after compressing and zipping the overall package size is about 132 MB.
- Create an IAM role. Since our primary objective is to test the limits we'll skip over the role creation process. Login to IAM Management Console with your credentials and create a Test-role and attach AWSLambdaRole policy.


- Create a Lambda function via AWS CLI and upload our deployment package directly to the function.
aws lambda create-function --function-name mlearn-test --runtime nodejs6.10 --role arn:aws:iam::XXXXXXXXXXXX:role/Test-role --handler tensorml --region ap-south-1 --zip-file fileb://./MachineLearning.zip
Replace XXXXXXXXXXXX with your AWS Account id. However since our package size is greater than the 50MB specified limit, it throws an error.
An error occurred (RequestEntityTooLargeException) when calling the UpdateFunctionCode operation: Request must be smaller than 69905067 bytes for the UpdateFunctionCode operation
- Since our deployment package is quite large we will load it again during an AWS Lambda inference execution from AWS S3. For this we need to create an AWS S3 bucket from AWS CLI:
aws s3 mb s3://mlearn-test --region ap-south-1
This will create an S3 bucket for us. Now we'll upload our package to this bucket and update our Lambda function with the S3 object key.
aws s3 cp ./ s3://mlearn-test/ --recursive --exclude "*" --include "MachineLearning.zip"
Once our package is uploaded into the bucket we'll update our Lambda function with the package's object key.
aws lambda update-function-code --function-name mlearn-test --region ap-south-1 --s3-bucket mlearn-test --s3-key MachineLearning.zip
This time it shows no error even after updating our Lambda function and we're able to upload our package successfully.
Result: The package size can be greater than 50MB if uploaded through S3 instead of uploading directly.
However, since our package size is about 132MB after compression, we are still not clear what the maximum limit of the package to be uploaded can be.
Test 2: What is the Maximum Package Limit?
- In order to get the maximum limit, we'll create a random data of about 300MB and upload it through S3 and update our Lambda function.
fsutil file createnew sample300.txt 350000000
- This will create a sample file of about 300 MB. We'll zip the file and upload it again through S3.
aws s3 cp ./ s3://mlearn-test/ --recursive --exclude "*" --include "sample300.zip"
aws lambda update-function-code --function-name mlearn-test --region ap-south-1 --s3-bucket mlearn-test --s3-key sample300.zip
- After updating our Lambda function we get the following error:
An error occurred (InvalidParameterValueException) when calling the UpdateFunctionCode operation: Unzipped size must be smaller than 262144000 bytes
The error describes that the size of the unzipped package should be smaller than 262144000 bytes, which is about 262MB. This size is just a little more than the specified limit of 250MB size of code/dependences that can be zipped into a deployment package (uncompressed .zip/.jar size).
Result: The maximum limit of the size of an uncompressed deployment package is 250MB when uploaded via S3. However we can't upload more than a 50MB package when uploading directly into a Lambda function.
The important thing to notice here is that your code and its dependencies should be within 250MB size limit when in an uncompressed state. Even if we consider a larger package size it may seriously affect Lambda function's cold start time. Consequently, the Lambda function will take a longer time to execute with larger package sizes.
AWS Lambda Cold Starts
Cold Starts have been a massive issue with FaaS as they can make functions slower to startup, which is counterproductive to the greater efficiency benefit.
Many efforts have been made to solve AWS Lambda cold starts or educate on how to handle them with many having helped the issue, but none really solving it.
However, AWS has made great progress on the area with the Provisioned Capacity feature announcement. As the function scales up, instead of waiting for new requests to come in before provisioning resources to serve them, AWS will proactively provision new instances of the function in advance. This behavior guarantees the performance that every request will stay within double digit milliseconds, up to the Provisioned Concurrency threshold set to the function. There are some caveats that developers should be aware however, for example, it makes your functions ineligible to the Lambda Free Tier.
Lambda Provisioned Concurrency is generally available in several regions and already integrated with AWS SAM, CodeDeploy and other serverless frameworks.
Learn everything about this feature and follow a step-by-step guide in our Knowledge Base.
Failure Detection for AWS Lambda
Traditionally in white-box monitoring, error reporting has been achieved with third party libraries that catch and communicate failures to external services and notify developers whenever a problem occurs. However there are a plethora of reasons why this isn't suited to AWS Lambda, the most critical being that error-handling libraries in the code are blind to Lambda specific failures, such as timeouts, wrongly configured packages and out of memory failures. In addition, there is an issue with coverage; implementing error reporting manually for each function is a lot of work and filled with potentially endless blindspots in your system.
Luckily, those problems can be solved quite easily and in most cases it's just a matter of adopting new tooling and development practices.
Observability
Observability doesn't mean that you'll have visibility but rather that the system makes itself understandable by outputting data, which then enables the developer to ask any kind of question about the current or past state of the system. Fortunately the information emitting aspect is well implemented in AWS with serverless users for example having an opportunity to get visibility without specifically implementing extra stuff in their code.
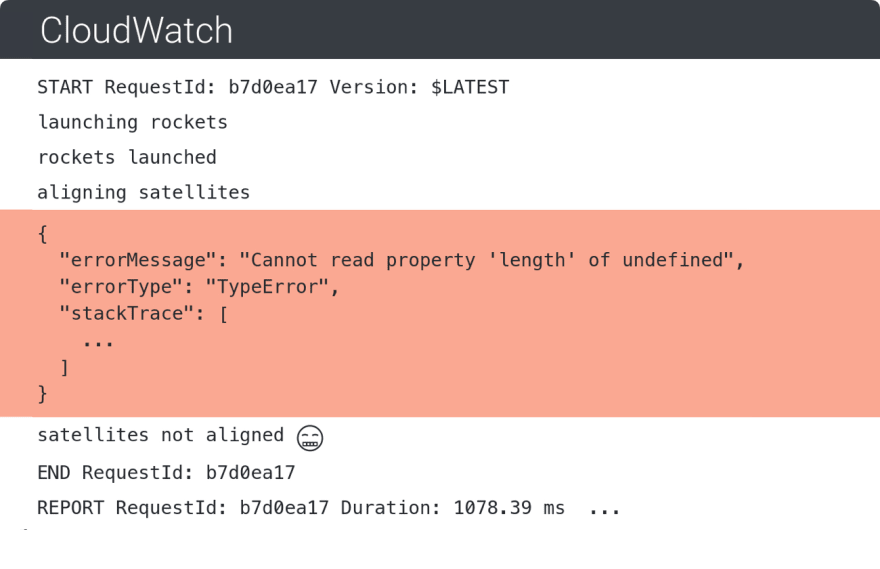
As well as CloudWatch logs, we could leverage AWS APIs for resource discovery, and X-ray and CloudTrail for tracing and connecting execution flows.
The ability to detect failures across all functions and connect them with specific invocations, view logs and pull X-ray traces for them significantly reduces the average time to resolution in failure scenarios.

Breaking It Down
The only prerequisite for log-based error detection and visibility in general is that logs are pushed to CloudWatch (in most cases that is the default). From there on, we can do some smart pattern matching and deduction to detect failure scenarios.
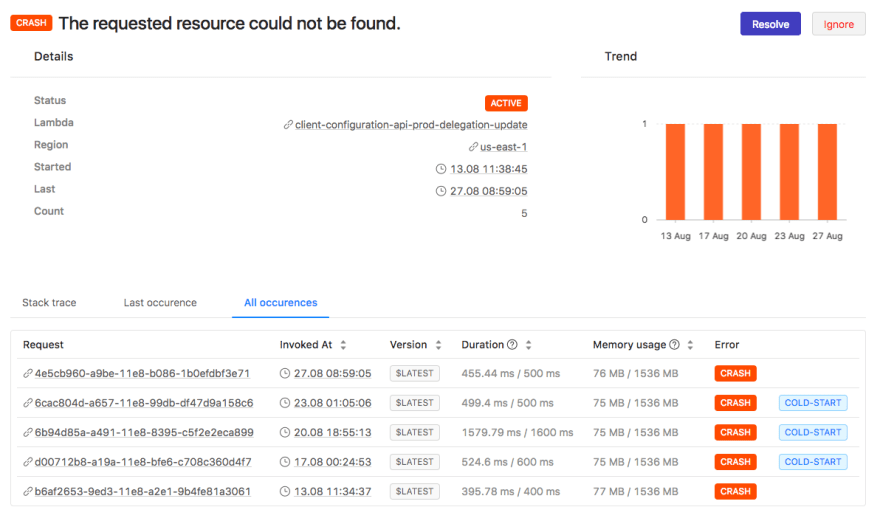
In addition, logs contain a lot of other data that indicate latency and memory usage and allow us to connect requests with AWS X-ray and search for a trace report for a specific request. All this allows us to gather a lot of context in order to understand what went wrong in a particular case.
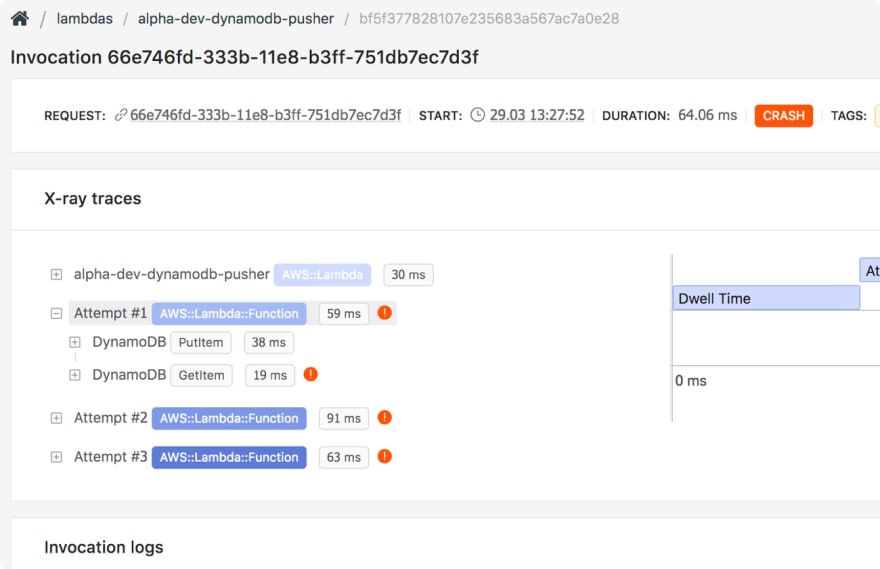
Here's what an X-ray trace contains when you search for a specific Lambda request; this enables you to catch errors in services your Lambda function touches.
Monitoring AWS Lambda
Monitoring your AWS Lambda performance is a crucial part in your everyday AWS Lambda usage. Monitoring helps you identify any performance issues, and it can also send you alerts and notify you of anything you might need to know. The world is slowly getting to a point where machines and computers will be flawless, but until then, if we let them perform various tasks for us, we could at least monitor their performance.
Improving Lambda Functions with Performance Metrics
Monitoring means improvements can be made in your architecture. The memory usage, for example, can be helpful in order to optimize resource allocation. Suppose a particular Lambda was assigned 1,024 MB of memory but has used at maximum 40% over the last 30 days. The function could have its memory allocation reduced to 512MB and still function perfectly.
Duration metrics are also helpful in identifying execution outliers. When minimum and maximum durations are too far from the average, the function presents a high variability in terms of how long it takes to answer a request. In many cases that will be expected, but when it isn't normal, monitoring can help in identifying which areas of your Lambda stack deserve more attention.
Closely monitoring the underlying service infrastructure usage and related costs can be the difference to being under or over budget. Dashbird provides costs broken down by Lambda aggregated with a resolution of an hour or a day. Analyzed together with the invocations count metrics, aggregated costs can provide a measure of how well your application is performing in comparison with the cost expected in the company's financial projections.
Advanced serverless observability and debugging
Dashbird is excellent in providing error alerts and monitoring support. Dashbird collects and analyzes CloudWatch logs while zeroing the effects on your AWS Lambda performance. All key information is available on a quick and easy to understand dashboard including an overview of all invocations, top active functions, system health and recent errors. Going down to invocation level data, you can also analyze each function separately.
Simple integration with your Slack account brings alerts about early exits, crashes, cold starts, timeouts, runtime errors, etc. into your development chat. Dashbird's error diagnostics, advanced log searching, and function statistics are also a few of its many benefits.
Dashbird's detailed views for performance tracking, optimization and error handling, tracking and error monitoring, and troubleshooting make it an ultimate Serverless monitoring tool; providing an easy overview of your Serverless infrastructure including invocation volumes, latency, failures, and overall health.
Dashbird won't only just just show you data! Dashbird features a rule engine that constructs periodic checks against resource data, identifying failures proactively, spotting inefficiencies, security and compliance issues, and recommending tailored ways to improve and further bullet-proof your app based on Serveress Well-Architected best practices.
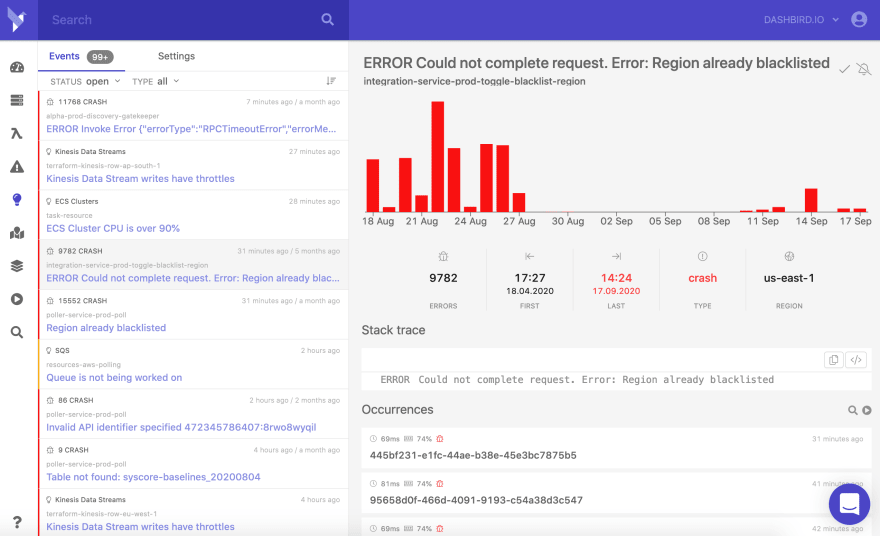
Rest assured that everything in your application is running smoothly. Dashbird's preconfigured alarms listen to events from logs and metrics, catching code exceptions, slow API responses, failed database requests and slow queues. Dashbird will alert you via email or Slack in seconds if something goes wrong, identifying the root-cause, so that you can jump straight in and fix.

In case you wish to learn more about the specific technical working principles of each platform and to compare them for pros and cons, or even to see what benefits they have, check out the documentation, and you'll be able to find much more information.
Find out more about the most prominent serverless observability platforms on the market in this comparison table.
There you have it! Our three-part series on What is AWS Lambda. We hope it's been helpful and insightful.


















