
This is the second article in a series of regex articles. In the first article, you can read about common use cases for regex. This article explains everything you need to know about regex for daily usage, with both examples and cheat sheets. An upcoming article will later explain the most advanced use cases of regex, which unleashes the real power of regex, but which are rarely used.
In This Article
- Explain Regex Like I'm Five
- What is the Syntax for Regex?
- Most Common Regex Flags
- Start and End of Regexes
- Regular Characters (Literal Characters)
- Special Characters (Metacharacters)
- Multi-Special Characters
- List of Regular Characters in Regex
- List of Special Characters in Regex
- Special Tokens
- Quantifiers - Repetition of Characters
- Character Classes
- Negative Character Classes
- Combine Character Classes with Quantifiers
- Regex Groups 101 - Or Operator
- Greedy Modifier
- Become a Regex Sensei
Explain Regex Like I'm Five
Regex (or Regular expressions) is a language for searching for and matching patterns in text, using special characters to describe the type of characters or sequence of characters you want to find or replace.
Most fundamental thing to understand about regex is how it works when you don't write any kind of special characters or use any of the regex language specific features. In that case, each written character in the regex, will match the corresponding character in a text, if those characters are present in the text, just like a regular text search field.

Results for when searching a text with the regex /all/gm
In the picture above, we can see the exact matches a regex will find in a string for the regex /all/ with the flags g and m. It finds a total of six matches in the string.
Note that the regular expression is only used to find those six matches. What we want to do with the matches is up to us. A common thing to do is to replace the matched characters with other characters. In other case it is only necessary to know whether a text matches a regex or not, for example to be able to detect if a user has entered a valid email or not. To learn more about what regex is used for, please read the previous article in this series.
What is the Syntax for Regex?
Regexes are often defined in between two forward slashes and followed by a few letters.
// Common syntax for a regex.
/someregex/ig
The slashes only defines that it is a regex we are writing, and the trailing letters are called flags which can alter how the regex should be interpreted.
In some languages we can define regexes in another way. For example, in JavaScript, you can use the RegExp constructor.
// In JavaScript you can define a regex with a regex constructor.
const myRegex = new RegExp('someregex', 'i');
// Above is the same as defining a regex with the standard slashes syntax.
const myRegex = /someregex/i;
In UIs, such as search fields in IDEs, it's common to allow regexes by enabling a regex button. When doing that, you normally don't need to write the surrounding slashes, and flags are sometimes possible to edit, but not always.

You can activate regex in VS Code search field with the button with the .* icon
A short note before we continue explaining flags. You should be aware of that the regex syntax can differ slightly between implementations in different programming languages. They do not all interpret regexes exactly the same, but most of them adhere very well to the standard.
Most Common Regex Flags
There are many regex flags. All languages and editors do not support all of them. I will therefore only present the most common ones here, which normally is supported.
The i and the g flag is far most used. The s and m flag is also something you will have to use some day, but not for certain.
Flag: i
The regex flag i, is the easiest flag to understand. What it does is to make the regex interpretation case insensitive. This means that the regex will match both capital and lower-case letters regardless of what you write. Without specifying this flag, regexes are case sensitive.
// This regex will not find a match in the string "Regex explained",
// since "Regex explained" has a capital R in it.
/regex explained/
// When using the i flag, this regex will match "Regex explained" string.
/regex explained/i
Flag: g
Another very common flag is the g flag, short for global. That flag tells the regex interpretator to find all matches of the regex expression rather than only finding the first match, which it will do without the flag. That is best explained with a picture!

The g flag tells the regex engine to find all possible matches, not just the first one
The tricky part here is probably not to understand what the g flag does, but when it matters. If you use a regex to only test if a text matches a pattern, such as when checking if a text contains your name, then the g flag doesn't really matter. Regardless of whether you find your name once, twice or a thousand times, the answer will be that it contains your name. The only difference is that the regex engine will have to work harder to find all thousand occurrences.
If you use the regex for another purpose, such as replacing all occurrences of a word in a text, then the g flag is something you would want, otherwise you would only replace the first occurrence of the word!
const text = 'What is regex? What can you do with regex?';
// Without the g flag, regex engine will only replace the first match of the regex.
console.log(text.replace(/regex/, 'love'));
// Output: What is love? What can you do with regex?
// With g flag, regex engine will replace all matches of the regex.
console.log(text.replace(/regex/g, 'love'));
// Output: What is love? What can you do with love?
Flag: s
s stands for single line. It effectually means that the regex will be treated as a single line even if it contains new lines. Normally regexes will not search for matches over multiple lines. What it means in regex language, is that the dot regex character, which means any character, can match newline characters (\n).

The s flag lets the regex engine ignore new line characters and treats the whole string as a single line
In the example above, the .* part of the regex means any amount of characters. That will be explained more in detail later in the article. For now, it's sufficient to understand that the s flag allows regexes to stretch over multiple lines.
Flag: m
m flag stands for multi line. Confusing? Didn't we just explain that above when we talked about single line? Don't worry, no need to raise a white flag.
While the s flag affects how the dot character is interpreted in a regex, the m flag affects how the start and end characters ^ and $ should be treated. Let's move on to talk about them now, m flag will be further explained there.

Wouldn't it be better if they just had worked together?
Start and End of Regexes
Writing a regex that ensures that a string starts and/or end with certain characters is a very common use case. Regex language uses a caret (^) to express the beginning of a string and a dollar sign ($) to represent the end of a string.
Normally, the start and the end of a regex indicates the start and end of the whole string the regex searches in, regardless of the number of lines in the string. The m character, changes the meaning of the caret and dollar sign so they instead represent the start and end of each line in a regex. In practice, that means that each newline character (\n) in the searched string will be treated as an end of a line, and also a start of a new line.
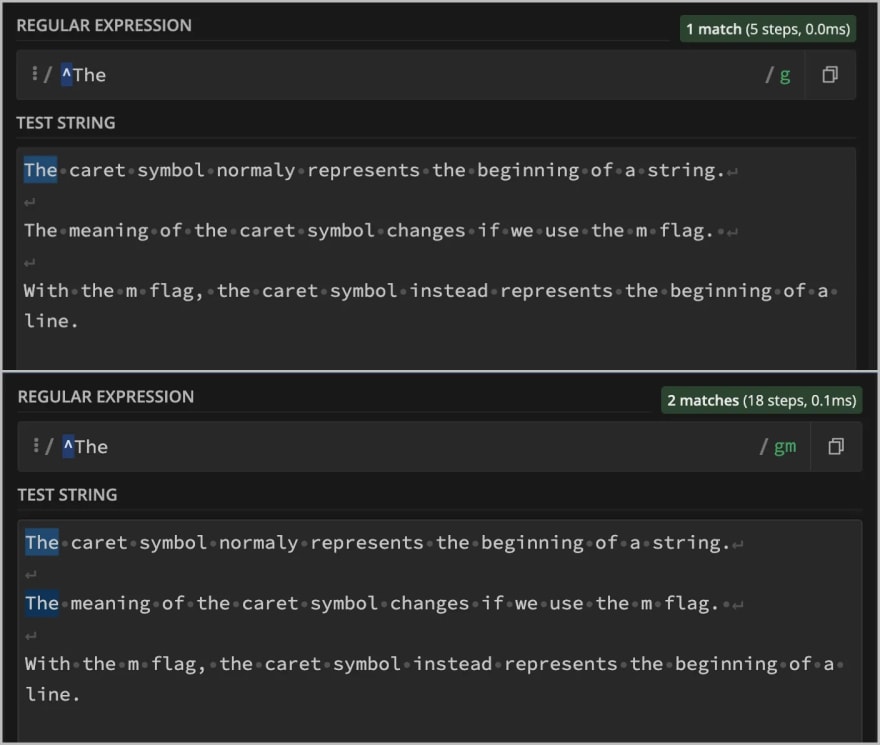
The m flag changes the meaning of caret (^) symbol to match the beginning of a line instead of begging of the whole string
Note that we cannot always expect the caret and dollar sign to match start end ends of strings. That's probably why regex is such a complex language, because it changes meaning of characters dependent on the surrounding characters. Let's talk a bit about that, to clarify which characters are normal in regex and what all the special characters do.
Regular Characters (Literal Characters)
Alternative names: regular characters, literal characters
Flags, special characters, dots and carets which change meaning with flags... Are there no regular characters in regexes? Yes! There are! They are called literal characters and you can safely use those characters without having to worry about them being treated in a strange way.
- Letters: a-z, both in upper-cases and lower-case
- Numbers: all numbers, 0 to 9
Ya, that's about it... Wasn't that many after all.
Just joking, there's a lot of them! You have @, & and % for example. Actually most characters are regular characters. It is easier to learn which characters has a special meaning in regex and then expect every other character to be a regular character.
Special Characters (Metacharacters)
Alternative names: special characters, metacharacters
The regex syntax includes quite many special characters which are used by a regex engine to understand the regex. These characters are called metacharacters. Metacharacter is a general term for a character that has a special meaning to a computer program, interpretator or in this case, a regex engine.
One example of a special character is the plus sign character (+) which means that the preceding character should exist one or multiple times (see quantifiers section). If you want the regex to interpret a special character as the character literal itself, you will need to escape it with a backslash character (\).
// The + character means that the character before it should exist at least once.
Regex /bun+y/ will match string "buny".
Regex /bun+y/ will match string "bunny".
Regex /bun+y/ will match string "bunnny".
Regex /bun+y/ will NOT match string "buy", because one n is required by the + sign.
Regex /bun+y/ will NOT match string "bu+y", because the plus character is treated as a metacharacter.
// If you want to match a + sign, you will need to escape it with a backslash.
Regex /bun\+y/ will match string "bun+y".
So in short, a special character is a character that needs to be escaped if it should be treated as the character itself in a regex. If not escaped, it will be a part of the regex syntax to describe to the regex engine how to interpret the regex.
We will soon see a full list of special characters in regex, but before that, we should look at what I call multi-special characters.
Multi-Special Characters
Alternative names: special characters, metacharacters
Let's be honest, multi-special characters is not an official term, it's just something I am making up right now. That's because I need a way to differentiate multi-purpose special characters from singe-purpose special characters.
The confusing thing with regexes is that special characters aren't always special. Other special characters are always special, but they change meaning when combined with other special characters. That's why I refer to these special characters as multi-special, special characters which plays many roles in the regex syntax.
Luckily, there are not very many multi-special characters. One very important one though, is the hyphen character (-). It is normally interpreted as a regular hyphen character, but when a hyphen is used within a character class (square brackets), it is instead treated as a range character that defines a range of characters.
// A hyphen in a regex is normally treated as a hyphen literal.
Regex /a-d/i will match string "a-d".
Regex /a-d/i will NOT match the strings "a", "b", "c" or "d".
// Within square brackets, hyphen is treated as a range character.
Regex /[a-d]/i will NOT match strings "a", "-" or "d", because the hyphen is in a character class.
Regex /[a-d]/i will match the strings "a", "b", "c" and "d", because a-d is treated as a range of characters.
// If you want to match a hyphen in a character class, you need to escape it.
Regex /[a\-d]/i will match strings "a", "-" and "d", because hyphen is escaped.
// Meaning of square brackets is explained in detail in character classes section.
As mentioned before when talking about start and end characters, the caret character (^) can also change its meaning in regex. Just as the hyphen, it behaves differently within square brackets. It's then called negative character classes, which we will look at later in this article.
Now answer, does multi-special characters confuse you? No worries. You can think of them as any other special character, only thing you need to take with you is the knowledge that some special characters can be used for multiple things.

List of Regular Characters in Regex
| Character | Comment |
|---|---|
| Letters | Letters a-z, both in upper-case and lower case. |
| Language Specific Letters | Often supported and treated as regular characters. |
| Numbers | All numbers are regular characters. |
| & | Ampersand is a regular character in regex. |
| @ | At sign is a regular character in regex. |
| , | Comma is a regular character in regex. |
| # | Hashtag is a regular character in regex. |
| % | Percentage sign is a regular character in regex. |
| _ (underscore) | Underscore is a regular character in regex. |
This list isn't complete since there are endless of regular characters. If in doubt, look in the list of special characters which is a complete list.
List of Special Characters in Regex
Each special character is described in detail in this article. This list also refers to the terms lookahead and lookbehinds. Those are used for advanced use cases and will be explained in another article.
| Character | Comment |
|---|---|
| - (hyphen) | Treated as a hyphen literal, or a range character if it's within a character class. Will need to be escaped to be treated as a hyphen when it's used in character classes. |
| = | Equal sign is treated as a regular character unless it is used to define a lookahead or lookbehind expression, (?=) or (?<=). |
| ! | An exclamation mark is a regular character unless it is used to define a negative lookahead or negative lookbehind expression, (?!) or (?<!). |
| ? | A question mark is a quantifier for an optional character. Can also serve as a greedy modifier when it follows a quantifier, which is explained at the end of this article. Lastly used in lookahead and lookbehind syntax when placed as the first character in a set of parentheses (?!), (?=,) (?<=) or (?<!). |
| {} | Used in syntax for quantifiers and is otherwise treated as regular curly braces. |
| [] | Square brackets are the syntax for character classes. |
| \ | Backslash is used to escape characters or to write special tokens such as newline character (\n). If you need to match a backslash sign, you need to escape it with another backslash. |
| + | Plus sign is a quantifier to tell that the preceding character or should be matched one or more times. |
| * | Asterisk is a quantifier to tell that the preceding character or should be matched zero or more times. |
| . | A dot character is used to match any other character. Will only match a single character unless combined with a a quantifier. It does not match a newline character unless the s flag is used. |
| pipe | Pipe character is used as an or operator. |
| / | Slash i often used to enclose a regex in programming languages. It will have to be escaped with a backslash if it should be treated as a slash literal. |
| " | Double quote is treated as a regular character in regex, but may need to be escaped in programming languages if the regex is a part of a string that is defined with double quotes. |
| ' | Singe quote is treated as a regular character in regex, but may need to be escaped in programming languages if the regex is a part of a string that is defined with single quotes. |
| <> | Less than and greater than characters are treated as regular characters unless they are used to define a positive or negative lookbehind expression, (?<=) or (?<!). |
| ^ | Caret is used to define the start of the string. When the m flag is used, it matches the start of each line separated by a newline character (\n). Carets are also used in the syntax for negative character classes, [^]. |
| $ | Dollar sign is used to define the end of a string. When the m flag i used, it matches the end of each line separated by a newline character (\n) will be treated as the end of a line. |
| () | Parentheses are used to define character groups. |
Special Tokens
Alternative names: special characters, metacharacters
When googling regex you will see people name things differently on every site. Therefore you may know special tokens as just metacharacters, special characters or just tokens. In this article, I do call them special tokens, because syntactically they look different to the other special characters in regex.
Looking at the syntax, they are kind of the opposite to other special characters, because special tokens use the backslash escape character, in front of an otherwise normal character literal, to make it be interpreted as a special character.
Below is a list of special tokens. As you can see, it is possible to write most of them in alternative ways. This table is not complete. Many special tokens has been omitted here since they are rarely used or seen.
| Token | Description | Alternatives |
|---|---|---|
| \d | Matches a single digit | [0-9], [0123456789] |
| \D | Opposite to \d. Matches any character that isn't a digit | [^0-9], [^0123456789] |
| \w | Matches any letter in alphabet, any number and underscore | [a-zA-Z0-9_] |
| \W | Opposite to \w. Matches any character that is not a number, underscore or a letter in the latin alphabet | [^a-zA-Z0-9_] |
| \s | Matches a whitespace character | Regular space character usually works, but note that also tabs, new lines and a few other whitespace character exist. |
| \S | Opposite to \s. Matches any character but whitespace | See \s for more info. |
| \n | Matches a newline character | |
| \r | Matches a carriage return character | |
| \t | Matches a horizontal tab character | |
| \b | Matches a word boundary, which is the start or end of a word. So the regex /\bex/ matches ex in example, but not the ex in regex. | One may think whitespace character \s would be the same as \b, but unlike \b, \s doesn't work in the beginning or end of a sentence, since there are no whitespaces there. |
| \B | Opposite to \b. Ensures that it isn't the beginning or end of a word. |
Quantifiers - Repetition of Characters
Alternative names: occurrence indicators, repetition operators
Normally when writing a character in a regex, the regex engine will only match one and exactly one of that character. There are some special characters in the regex syntax which can be used to change that behavior. These special characters are called quantifiers and are always placed directly after the character it will affect.
As an example, the question mark character means that the previous character should be present 0 or 1 times, which basically means that it's an optional character. The question mark can for example be used to accept both American and English spelling.
// The question mark quantifier can be used to match a character zero or one time.
Regex /colou?r/ will match the string "color".
Regex /colou?r/ will match the string "colour".
Regex /colou?r/ will NOT match the string "colouur".
All other quantifiers work in the same way. They demand the preceding character to be repeated a certain amount of times.
| Character | Description | Example | Match | No Match |
|---|---|---|---|---|
| ? | Matches the preceding character zero or one time | bun?y | buy, buny | bunny |
| * | Matches the preceding character zero or more times | bun*y | buy, buny, bunny | |
| + | Matches the preceding character one or more times | bun+y | buny, bunny | buy |
| {2} | Matches the preceding character exactly two times | bun{2}y | bunny | buy, buny, bunnny |
| {2,4} | Matches the preceding character two to four times | bun{2,4}y | bunny, bunnny, bunnnny | buy, buny, bunnnnny |
| {2,} | Matches the preceding character two or more times | bun{2,}y | bunny, bunnny, bunnnny, bunnnnny | buy, buny |
Character Classes
Alternative names: bracket expressions
Syntax: []
Character classes is a very important part of regex. It allows you do declare a set of characters to match instead of specifying one exact character to match. To use it, write all alternative characters within square brackets ([]).
// One and only one of the characters in a character group will be matched.
Regex /optimi[sz]ation/ will match both "optimization" and "optimisation".
Regex /optimi[sz]ation/ will NOT match "optimiation", because either s or z is required.
Regex /optimi[sz]ation/ will NOT match "optimiszation", because only one of s and z is allowed.
In the example above, you can see that when a character class is defined, a regex engine will only accept one of the characters in the group to be present. If you would want to match more than one of the characters, you can combine it with a quantifier.
// Combine a character class with a quantifier if you want to accept more
// than one of the characters within the group to be matched.
Regex /m[isp]+/ will match "mississippi".
Regex /m[isp]+/ will match "miss".
Regex /m[isp]+/ will NOT match "sim", because m must be placed before i, s and p.
In many cases, you may want to put a lot of characters into a character class. Declaring all of them can be cumbersome though. In that case, you can define a range of characters in the character class. The syntax for a range is two characters with a hyphen in between them, such as a-z and 0-9.
Regex /[a-z]/ will match any one character in the alphabet.
Regex /[a-z]/ will NOT match a number.
Regex /[a-z]/ will NOT match a whitespace character.
Regex /[a-z]+/ will match any characters in the alphabet, one or multiple (i.e. a word).
Regex /a[a-z]+/ will match any word starting with the letter a.
Regex /a[a-z]+a/ will match any word starting and ending with an a.
Regex /a[a-z]+a/ will NOT match "a hyena", because whitespace is not included in the character class.
Regex /a[a-z ]+a/ will match "a hyena", because whitespace is now included in the character class.
Regex /a[a-z\s]+a/ will match "a hyena", because \s represents a whitespace character.
You can define any number of ranges in a character group, just add them as you need.
Regex /[1-3]/ will match one of the integers 1, 2 and 3.
Regex /[1-36-9]/ will match one of the integers 1, 2, 3, 6, 7, 8, 9
Regex /[6-91-3]/ is the same as above, just a suspicious way to write it...
Regex /[1-36-9]/ will NOT match any of the integer 4, 5 or 6.
Regex /[a-z0-9] will match any lower-case letter or any integer.
Regex /[0-15-7A-Ceg]/ will match any of the characters 0, 1, 5, 6, 7, A, B, C e and g.
// Remember that regexes are case sensitive without the i flag?
Regex /[a-z]/ will match any lower case letter.
Regex /[A-Z]/ will match any upper case letter.
Regex /[a-zA-Z]/ will match any letter, upper or lower case.
Regex /[a-z]/i will match any letter, upper or lower case, because the i flag is specified.
Now, do you remember reading about multi-special characters? Characters which can both behave as a regular character and a special character. A hyphen is one of those. Most often, it is treated as a normal character, but within a character class it is instead used as the range syntax. This also means that you will have to escape the hyphen character if you would want the character class to use it to find matches.
Regex /[a-c]+/ will match "aaa", "abc", "acb" and "cccccc".
Regex /[a-c]+/ will match NOT matchc "a-a", because it contains a hyphen.
Regex /[a\-c]+/ will match "a-a", "a-c", and "c-a", because the hyphen is escaped (and treated as a hyphen character).
Regex /[a\-c]+/ will NOT match "abc", because the hyphen is not a range character, so b is not included in the character class.
Regex /[a-c\-]+/ will match "a-a" and "abc", because we both have a regular hyphen and a range character in the character class.
Regex /a-[cd]/ will match "a-c" and "a-d", because a hyphen outside a character class is treated as a hyphen.
Regex /a-[cd]/ will NOT match "ac" or "ad", because the hyphen is required.
You will use character classes a lot when writing regex. Although, most of the times you will use the same ones over and over again. The ranges a-z, A-Z and 0-9 is very common to use in regexes, especially when they are combined with quantifiers to match any word or sequences of words.
Regex /[a-z]+/ will match any word, but no whitespaces.
Regex /[a-z\s]+/ will match multiple words.
Regex /the[a-z\s]+green/ will match any text that starts with "the" and ends with "green".
Observant readers may have noticed that I used the special token \s as a replacement for a whitespace within a character group in one of the examples here above. You can use the special tokens within character classes as normal, just as you would use them outside of a character class.
Regex /a\scobra/ will match "a cobra".
Regex /a\scobra/ will NOT match "acobra", because the whitespace is required.
Regex /a[abcor\s]/ will match "a cobra".
Regex /a[abcor\s]/ will match "acobra", because the whitespace is not required.
Negative Character Classes
Alternative names: negative bracket expressions
Syntax: [^]
When you write a caret (^) at beginning of a character class, it will be treated as a negative character class. Negative character classes are the opposite to character classes. They work in the same way as character classes, but instead of declaring which characters to be present, it instead defines which characters that must no be present.
Regex /pineapple/ will match "pineapple".
Regex /pin[e]apple/ will match "pineapple".
Regex /pin[^e]apple/ will NOT match "pineapple", because the letter e is not allowed between n and a.
Regex /pin[^e]apple/ will match "pinkapple", because it is only the e between the n and a that is forbidden.
Combine Character Classes with Quantifiers
Just as with regular character literals and special tokens, character classes only substitutes a single character unless combined with a quantifiers.
Regex /[0-9]/ will match 3 or 8, but NOT 38.
Regex /[0-9][0-9]/ will match 38, but NOT 3 or 8.
Regex /[0-9]{2}/ will match 38, but NOT 3 or 8.
Regex /[0-9]{1-2}/ will match 38, 3 or 8.
Regex /[0-1][0-9]{2}/ will match a three digit number starting with 0 or 1.
Regex /0[1-9]{2}-[0-9]{7}/ will match a phone number on format 0XX-XXXXXXX.
Regex /[0-1]+/ will match any binary number.
Regex Groups 101 - Or Operator
Groups is one of the most difficult things to understand with regex, and they are rarely needed in daily work. For that reason, they will be explained in the next article in this regex series. Right now, we will satisfy by look at a simple and very frequent use case of it, to include only one of two or more words in regex. To do that, we use the or operator, the pipeline character.
Regex /(a|b)c/ will match "ac" or "bc", but NOT "abc".
Regex /(a|b)c/ will NOT match "c", because a or b is required.
Regex /optimi(s|z)ation/ will match "optimisation" or "optimization".
Regex /(red|blue)/ will match "red" or "blue", but NOT "redblue" or "lue".
Regex /(red|blue) color/ will match "red color" or "blue color", but NOT " color".
Greedy Modifier
Alternative names: greedy quantifier, greedy operator
We have already seen that the question mark symbol can be used as a quantifier to specify that the preceding character shall be matched zero or one times. The question mark has another important usage in regex though, it is also used as the greedy modifier, which makes a quantifier "lazy" instead of "greedy".
Normally, quantifiers are greedy. This means that they will try to match as many characters as possible. If the greedy modifier is added after a quantifier, that quantifier will instead match as few characters as possible.

The greedy modifier makes the preceding character match as few characters as possible
Try greedy modifier on Regex101
Become a Regex Sensei
We have now went through almost everything there is to know about regex syntax. There are a few things left to know to take the step from regex expert to ninja. Those things will be covered in an upcoming article.
If you enjoy regex and puzzle games, you can the programmer puzzle game at my website. Regex will be needed to know for the more advanced levels!


















