
This post is part of a larger write-up on o11ycon, if you're curious to read more you can check out my full rundown here. If you'd like to connect, please follow me on dev.to or feel free to reach out on Twitter @dangolant.
Kicking off the second half of the day, Dr. Peter Alvaro surveyed the current state of fault tolerance research for the audience. Dr. Alvaro framed these current and historical approaches to fault tolerant system design as "myths" that the industry has come to believe in, and made a strong case for the un-sustainability of these practices, before offering his own proposed solution to at least some of our woes.
(in case it isn't obvious, I took some liberties with the heading titles)
Myth 1: Priests, And Their Infernal Magicks

The first myth Dr. Alvaro covered is that of Experts, with a capital E, the abstractions that they create, and research predicated on the genius of these individual visionaries of the field . In the past, technologists have been able to avoid some of the hardest problems that face us all by building on existing protocols and algorithms, dealing with things like reliable storage, message delivery, and secure cryptography through interfaces below which Only The Titans Roamed. This was a tenable situation when the pieces being abstracted were relatively constrained, and weren't themselves sitting on top of piles of what we have come to know are leaky abstractions. The problems we face today are of a different magnitude, and without taking away anything from the giants whose shoulders we stand on, even our best inventions have been shown to flake in corner cases. Essentially, Dr. Alvaro's assertion was that while experts wizards are capable of gifting the industry realms of men with amazing inventions, there comes a point at which even the smartest people on Earth cannot contain within their heads the knowledge and innumerable permutations of state & environment necessary to create abstractions that stand the tests we throw at today's distributed systems. He points to efforts like the stalled out NFS and the flaws of RPC and queueing as evidence that, when it comes to distributed systems, there is no perfect failure detector. If we cannot reliably detect failure, how can we even dream of asserting the validity of an abstraction?
Myth 2: Math Will Make The Pain Stop

That brings the Good Doctor to the second myth: Formal Verification. Formal verification relies on mathematical models that, when run with a sufficiently exhaustive set of states and transitions, prove a given algorithm or system is "correct" in achieving the stated goal in all cases. The problem here is that, in Dr. Alvaro's words, "you can't model check Netflix." He knows, because apparently attempts were made. Simulating one arbitrary fault in the system could be done fairly quickly (I had exact times written in a prior draft, but Notion ate it sooooo, just think small). Fault tolerance is dependent on resilience to combinations of faults though, and attempts at simulating all combinations of just four concurrent faults brought the running time of a model check up to 12 weeks. Because of this combinatorial nature of fault tolerance search, attempts at model checking anything more than 4 concurrent faults very quickly approach Heat Death Of The Universe type numbers. Attempts have been made at model checking subsets of the gestalt system, but this is still expensive, and can gloss over failures that stem from those systems' integration.
Myth 3: Numbers + Warlocks = Anything Other Than Numerology
The solution the industry came up with was to break down these applications into pieces or flows, and then selectively hunt down combinations in a given vector that start yielding fruitful faults. That approach has inevitably led to the rise of expert fault hunters, yielding a strange hybrid approach of our first two myths, and created our third myth. What Dr. Alvaro has dubbed "genius-guided walks" through the total field of possible fault combinations, are an untenable solution for an industry where applications are becoming more complex, because the approach relies too much on the intuition of a small handful of people, and yields an uneven and tough to measure result. Forgetting the fact that this small priest class of Combinations Magicians (in reality Chaos Engineers or Jepsen testers) become more expensive not only as a small set of systems grow more complex, but as the total number of complex, fault-sensitive systems grow, it's very hard to assess whether one of these practitioners is really solid in such a small field, and past that whether they can successfully execute their role if much of it is dependent on navigating an organization well. In short, there are too many damn variables.
Like I mentioned in the link to this post, my attempts to explain this particular talk are akin to a poodle being tasked with explaining trigonometry, so I highly encourage you to watch the talk once it's posted over at o11ycon.io, this is your final warning before I spoil the (pretty cool) solution Dr. Alvaro proposed.
Our Deliverance
The solution to all this madness is an approach Dr. Alvaro called Lineage Driven Fault Injection. Essentially, given the assumption that all fault tolerance is based on at least some form of redundancy, we can assume that all fault tolerance relies on either redundancy across time or or across space. An example of space-based redundancy is spinning up another instance of a server, while a type of time-based redundancy could be something like queueing retries when requests fail. The thing about these redundancy schemes is that they exist along certain execution paths, or lineages, as Alvaro puts it. By visualizing these flows side by side (there's a great slide in the talk that I don't want to spoil) you can start to see how cutting off certain points in a lineage is productive in exposing faults, while other strategies would obviously be moot. Say, given a model with a web client, a cluster of web servers behind it, a cluster of API servers behind that, and a cluster of DB servers behind those, you had to cause a service interruption, and you were allowed to cause two faults.
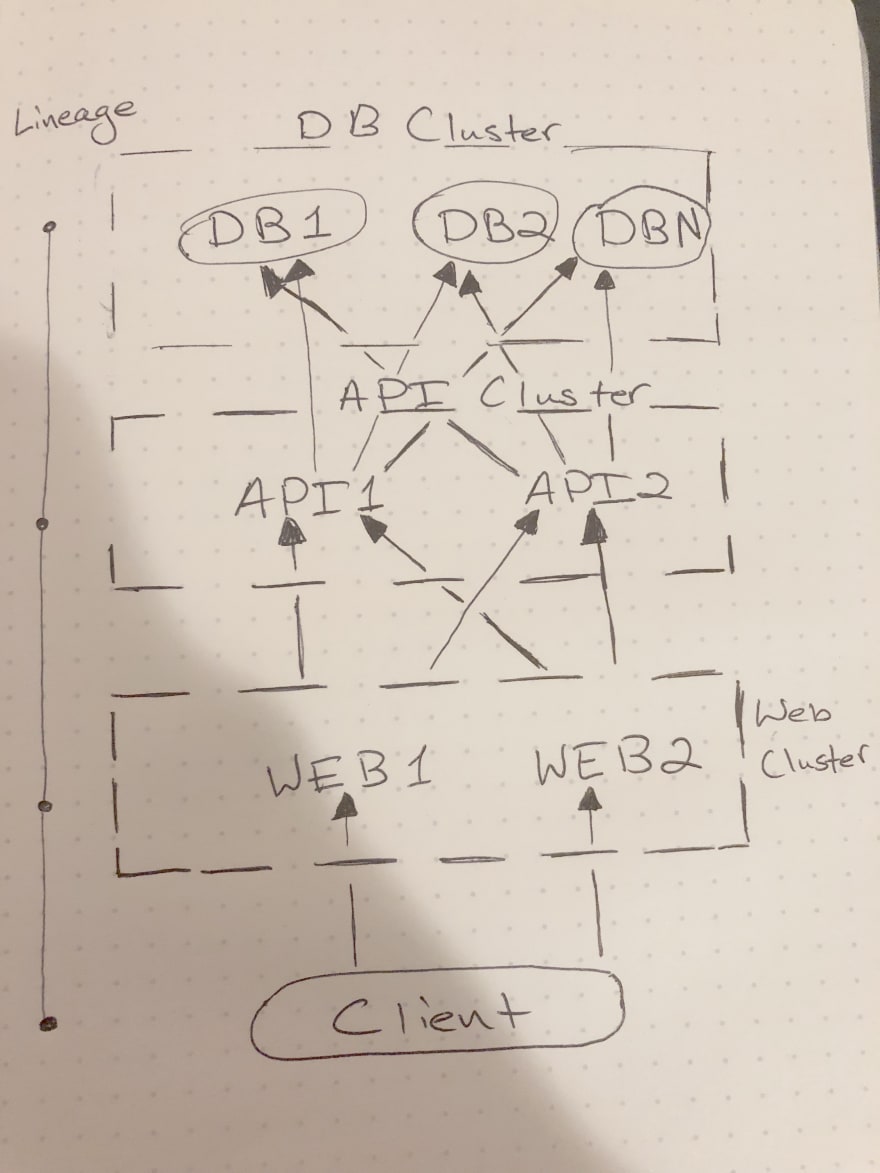
In the example above, it's likely clear that you would would want to knock out either the two API servers, or the two web servers. It's an oversimplified example, "knocking out" could be something as simple mildly degrading response times, and the goal in real life would most likely be a cascading failure caused by a shared dependency in multiple lineages. Despite that, you can probably see that it's a compelling approach that can be operationalized and then automated, precisely because it is so simple. The key is that it's dependent on being able to trace requests and see the context of those requests throughout your system, and therefore to benefit, you have to start building with observability in mind.
BEST QUOTE
If you have any take-aways from today's talk, the top three should be:
- Composability is the last hard problem
- Priests are human
- We can automate the peculiar genius of experts
I hope you enjoyed this recap of Dr. Peter Alvaro's wonderful talk at o11ycon. If you'd like to read my full recap of the day you can find it here, and if you'd like to connect feel free to follow me on dev.to or twitter @dangolant.


















