
I'm having an issue with how pandas could not preserve the data types of my table after writing process.
This is my table in which I read the data from SQL Server with my query.

And I simply code this line to write a new one hoping that it will yield the same result when I read it later.
df.to_excel('new2.xlsx', index=False, engine='xlsxwriter')
df2 = pd.read_excel('new2.xlsx')
And I ended up with this.
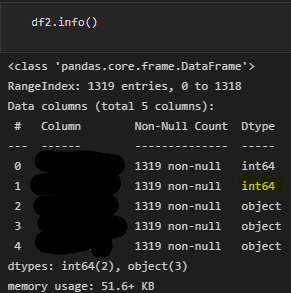
I'm having a hard time finding the right keywords and solutions on Stack Overflow. I've already read the pandas documentation but nothing covers my case.


















