
Woher wissen Sie, wo Ihre Daten gespeichert werden sollen? Und was passiert, wenn ein Speicherknoten ausfällt oder Sie einen neuen Speicherknoten hinzufügen, um Ihr System zu skalieren? Ein Hash ist eine gängige und effiziente Methode, um zu bestimmen, wo Ihre Daten in diesem Szenario gespeichert werden sollen, und es ist besonders wichtig, sie zu verstehen, wenn Sie irgendeine Art von Daten-Streaming-Anwendung implementieren.
Was ist Hashing?
Beim Hashing werden "Hash-Tabellen" und "Hash-Funktionen" oder Algorithmen verwendet, um Daten variabler Größe, wie z. B. eine Datei oder eine beliebige Zeichenkette, in eine konsistente Ausgabe fester Größe umzuwandeln.
Die Hash-Funktion (oder der konsistente Hash-Algorithmus) ist eine mathematische Operation, die Ihre Daten nimmt und eine Zahl ausgibt, um diese Daten zu repräsentieren, deren Wert weit geringer ist als die ursprüngliche Größe der bereitgestellten Daten. Die von der Hash-Funktion ausgegebene Zahl wird als "Hash" bezeichnet, und der Wert wird jedes Mal konsistent sein, wenn die Hash-Funktion mit denselben Daten aufgerufen wird. Sie können dann die Daten in der Hash-Tabelle nachschlagen
Ein SEHR einfaches Beispiel ist der Modulo-Operator (%) als Hash-Funktion: Unabhängig von der Größe der Zahl, die dem Modulo-Operator übergeben wird, liefert er eine konsistente Zahl innerhalb eines bestimmten Bereichs n für [Daten] mod n:
69855 MOD 10 = 5
63 MOD 10 = 3
916 MOD 10 = 6
26666 MOD 10 = 6
Das letzte Beispiel veranschaulicht eine "Kollision", bei der verschiedene Eingaben denselben Hash-Wert ergeben, nämlich 6. Sie können auch sehen, wie Sie den Ausgabebereich ändern können, indem Sie die Hash-Funktion anpassen, z. B. x MOD 20 oder x MOD 30.
In echten Hash-Implementierungen werden komplexere Hash-Funktionen verwendet, um Kollisionen zu behandeln und den Speicher je nach den erwarteten Eingabedaten möglichst effizient zu nutzen.
Warum Hashing?
Ein gängiges Beispiel für Hashing ist die Datenspeicherung und -abfrage. Angenommen, Sie haben eine Sammlung von 15 Milliarden Elementen und müssen ein bestimmtes Element abrufen; wie würden Sie das tun? Ein Mechanismus wäre, über Ihren Datensatz zu iterieren, aber das ist ineffizient, wenn die Anzahl der Schlüssel im Key-Value-Speicher wächst; es ist besser, einen Hash zu verwenden.
Dies würde wie folgt funktionieren:
Beim Speichern der Datenelemente führen Sie zunächst einen Schlüssel, der mit Ihren Daten verknüpft ist, durch eine Hash-Funktion. Basierend auf dem sich ergebenden Hash-Wert speichern Sie Ihre Daten in der Hash-Tabelle an der gehashten Stelle. Im Falle einer Kollision müssen Sie Maßnahmen ergreifen, um sicherzustellen, dass keine Daten verloren gehen; beispielsweise könnte die Hash-Tabelle eine verknüpfte Liste von Daten anstelle der Daten selbst speichern (bekannt als verkettetes Hashing), oder Ihre Hash-Funktion könnte so lange nach einem leeren Slot suchen, bis ein solcher gefunden wird (Techniken wie Probing oder Double Hashing).
Beim Abrufen von Datenelementen lassen Sie den Schlüssel, der mit Ihren Daten verknüpft ist, erneut durch die Hash-Funktion laufen und suchen dann den resultierenden Hash-Code in Ihrer Hash-Tabelle.
Wenn ich bereits einen Schlüssel für meine Daten habe, warum verwende ich diesen Schlüssel nicht direkt, um meine Daten zu speichern, z. B. als Index für ein Array? Das ist zwar möglich (dies entspricht der Verwendung einer Hash-Funktion, die nichts tut), aber sehr ineffizient. Was ist, wenn Ihre Schlüssel sehr groß und nicht zusammenhängend sind?
Hashing in einem verteilten System
Im vorigen Beispiel wurde die Verwendung einer Hash-Tabelle zum Speichern und Abrufen einer großen Liste von Datenelementen erörtert, aber was ist, wenn diese Liste physisch über mehrere Server verteilt ist?
Sie können eine Hash-Funktion verwenden, um zu bestimmen, wo die Daten in einem verteilten System gespeichert werden sollen. Anstelle der Hash-Funktion, die auf einen Ort in einer Hash-Tabelle zeigt, wie im vorherigen Beispiel, könnte ein verteiltes System eine andere Hash-Funktion verwenden, deren Ausgabe eine Server-ID ist, die auf eine IP-Adresse abgebildet werden kann.
Ein Beispiel: Wenn Sie Daten in einem verteilten System speichern, hacken Sie zunächst einen mit Ihren Daten verknüpften Schlüssel, um die Server-ID zu ermitteln, auf der Ihre Daten gespeichert werden sollen, und speichern Sie die Daten dann auf diesem Server. Wenn Sie eine Hash-Funktion gewählt haben, deren Ausgabe gleichmäßig auf alle verfügbaren Server verteilt ist, wird keiner Ihrer Server überlastet, und Ihre Daten können schnell abgerufen werden. In ähnlicher Weise können Sie auch einen Lastausgleich in Betracht ziehen, bei dem die Anzahl der Server erhöht wird, um die Serverlast auszugleichen.
Angenommen, Sie haben eine Liste von 5 Servern, auf denen Ihre Daten gespeichert werden können, und Sie haben jedem von ihnen eine eindeutige Identität von 1 bis 5 zugewiesen. In diesem Beispiel entscheiden Sie, auf welchem Server die Daten gespeichert werden sollen, und zwar auf der Grundlage eines Hash-Codes für den Schlüssel dieser Daten:
Erzeugen Sie einen Hash-Code, der den Schlüssel der zu speichernden Daten darstellt; der resultierende Hash-Code sollte im Bereich von 1 bis 5 liegen (da wir 5 Server haben)
Im vorigen Beispiel wurde ein sehr einfaches Modulo für die Hash-Funktion verwendet; das Äquivalent hier wäre, sich unsere Hash-Funktion als "
[Schlüssel] MOD 5" vorzustellen.Speichern Sie die Datei auf dem Server, dessen ID berechnet wurde.
Das funktioniert, aber was passiert, wenn ein Server ausfällt? Was passiert, wenn ein neuer Server hinzugefügt wird? In beiden Fällen muss für alle Daten der Hash neu berechnet und auf der Grundlage des Ergebnisses des neuen Hashs verschoben werden - dies wird als Rehashing bezeichnet und ist ineffizient, weshalb der obige Ansatz zu einfach ist, um in der Produktion verwendet zu werden.
Was ist konsistentes Hashing?
Beim konsistenten Hashing wird festgelegt, wo die Daten in einem verteilten System gespeichert werden sollen, wobei das Hinzufügen oder Entfernen von Servern toleriert wird, um die Datenmenge zu minimieren, die bei Infrastrukturänderungen verschoben oder neu gehasht werden muss.
Unterschied zwischen konsistentem Hashing und Hashing
Beim Hashing handelt es sich um eine allgemeine Technik, bei der eine variable Datenmenge so reduziert wird, dass sie in einer konsistenten Speicherstruktur mit fester Größe, einer so genannten Hash-Tabelle, gespeichert wird, um einen schnellen und effizienten Abruf zu ermöglichen. Die Größe der gewählten Hash-Tabelle hängt von der Menge der gespeicherten Daten und anderen praktischen Erwägungen ab, wie z. B. dem verfügbaren Systemspeicher. Wenn die Größe der Hash-Tabelle geändert wird, ändert sich in der Regel auch die Hash-Funktion, um sicherzustellen, dass die Daten gleichmäßig über die neu geänderte Tabelle verteilt werden, d. h. alle Daten müssen neu gehasht und verschoben werden.
Konsistentes Hashing ist eine spezielle Art des Hashings, bei der bei einer Größenänderung der Hash-Tabelle nur ein kleiner Teil der Daten verschoben werden muss. Die Anzahl der zu verschiebenden Datenelemente ist n/m, wobei n die Anzahl der Datenelemente und m die Anzahl der Zeilen in der Hash-Tabelle (oder der Server in unserem früheren Beispiel eines verteilten Systems) ist.
Wie funktioniert konsistentes Hashing?
Stellen Sie sich die Server (oder jeden anderen virtuellen Knoten), auf denen Ihre Daten gespeichert sind, in einem Kreis angeordnet und im Uhrzeigersinn nummeriert vor. Um die Sache intuitiver zu machen, werden die meisten Abbildungen die Knoten von 1 bis 360 (Grad) nummerieren, aber die tatsächlich gewählten Zahlen und ob sie zusammenhängend sind oder nicht, sind unwichtig; was zählt, ist, dass die zugewiesenen Server-IDs aufsteigen, wenn Sie eine Route im Uhrzeigersinn von einem Server zum anderen durch den Kreis verfolgen. Die ID des nächsten Knotens ist immer größer als die des vorherigen, bis er umrundet wird.
Um festzustellen, auf welchem Server die Daten gespeichert werden sollen, wird der Hash-Wert der Daten berechnet und dann der Modulus dieses Hash-Wertes mit 360 multipliziert; die sich daraus ergebende Zahl wird wahrscheinlich nicht genau mit einer gültigen Servernummer übereinstimmen, so dass die Server-ID ausgewählt wird, die der sich ergebenden Zahl am nächsten kommt und größer ist als diese. Wenn es keinen Server gibt, dessen ID größer ist als die sich ergebende Zahl, wird wieder bei 0 begonnen und weiter nach einer Server-ID gesucht.
Ein Beispiel:
Es gibt einen Datenschlüssel, auf den eine Hash-Funktion angewendet wird, deren Ergebnis 5562 ist.
5562 MOD 360 ist 162
Wir suchen den Server in unserem Einsatz, dessen ID größer als 162 ist, aber am nächsten dran ist, z. B. id 175 im untenstehenden Diagramm.

Was ist, wenn ich keine 360 Server habe? Oder mehr als 360 Server? Die Zahlen sind unwichtig, nur das Prinzip. Solange die ausgewählten Server-IDs in aufsteigender Reihenfolge nummeriert, einigermaßen gleichmäßig verteilt und konzeptionell in einem Ring (bekannt als Hash-Ring) angeordnet sind.
Warum ein einheitliches Hashing?
Wenn unsere Daten über mehrere Knoten (oder Server) verteilt sind, wird es viel effizienter, einen Knoten zu unserem System hinzuzufügen oder zu entfernen. Nehmen wir ein Beispiel, bei dem wir drei Knoten, A, B und C, mit den IDs 90, 180 und 270 haben. Jeder Knoten in unserem Setup enthält ein Drittel der Daten.
Wenn wir einen neuen Knoten, D, hinzufügen wollen, weisen wir ihm eine neue ID zu, sagen wir 360.
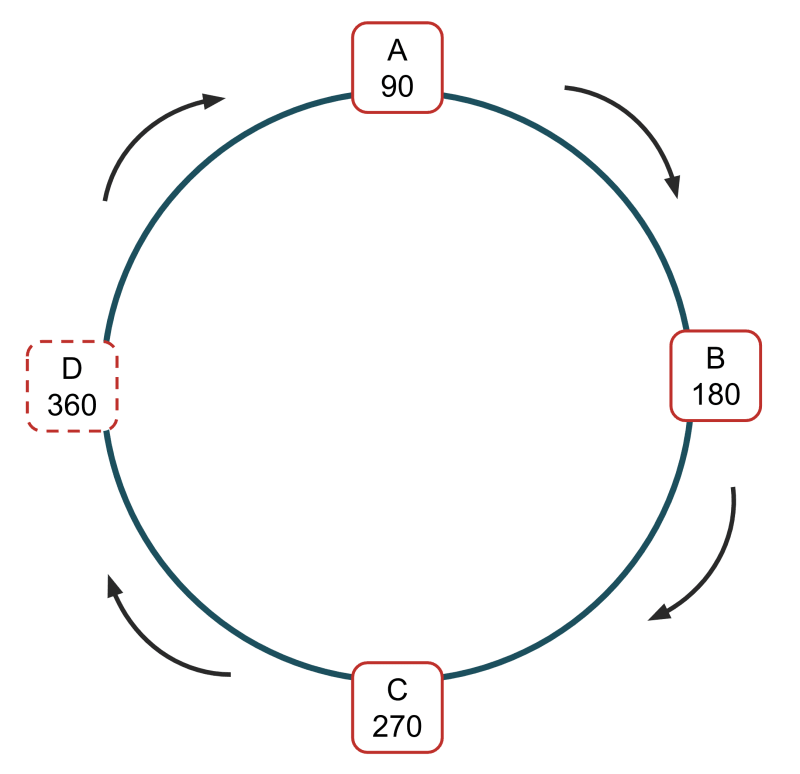
Wir haben nun die Wahl, ob wir D leer lassen und zulassen, dass es sich langsam füllt, wenn Daten gespeichert werden, oder ob wir Daten von anderen Knoten in D umverteilen. Welche Wahl wir treffen, hängt von der implementierten Lösung ab; Web-Caching- und Cache-Server-Implementierungen werden Ersteres tun und zulassen, dass Cache-Misses D langsam füllen. Andere Lösungen nehmen die Hälfte der Daten von A und übertragen sie nach D (ohne zu tief in die Mathematik einzusteigen, müssen die übertragenen Daten einen Hash haben, dessen Wert dazu führen würde, dass sie in D gespeichert werden, wenn es neue Daten wären).
Was ist ein konsistenter Hash-basierter Benennungsdienst?
Die vorangegangenen Beispiele in diesem Beitrag betrafen die Speicherung von Daten oder Dateien auf Servern, aber das Prinzip kann auf die verteilte Speicherung beliebiger Daten ausgedehnt werden. Namensdienste gehören zu den größten und am meisten verteilten Systemen, die geschaffen wurden, und eignen sich gut für die Implementierung von konsistentem Hashing. Lassen wir DNS für den Moment beiseite, das eine spezifische und andere Implementierung hat, so könnten wir einen allgemeineren Namensdienst mit konsistentem Hashing wie folgt implementieren:
Namenseinträge werden auf mehreren Servern gespeichert.
Den Servern sollte eine ID zugewiesen werden, die in aufsteigender Reihenfolge in einem konzeptionellen Ring angeordnet ist.
Um einen Namen aufzulösen, müssen wir den Server ausfindig machen, auf dem der Namenseintrag gespeichert ist.
Man nimmt einen Hash des Namens und multipliziert das Ergebnis mit 360 (unter der Annahme, dass wir weniger als 360 Server haben)
Suchen Sie die ID des Servers, dessen Name dem im vorigen Schritt gefundenen Ergebnis am nächsten kommt, aber größer ist als dieses. Wenn es keinen solchen Server gibt, gehen Sie zum ersten Server im Ring mit der niedrigsten ID über.
Der Namenseintrag wird auf dem identifizierten Server gefunden.
Sie können auch Content-Delivery-Netzwerke in Betracht ziehen, die auf ähnliche Weise arbeiten, indem sie Anfragen auf verschiedene Knoten verteilen, um Hot Spots zu vermeiden.
Konsistente Hashing-Implementierung
Auf Github sind mehrere Implementierungen verfügbar, von Java bis Python, bei denen eine Reihe von Knoten in einem konsistenten Hashing-Ring angeordnet sind, der eine verteilte Hash-Tabelle enthält.
Es gibt produktive Speichersysteme, die konsistentes Hashing verwenden, wie Redis, Akamai oder Amazons Dynamo, von denen viele komplexere Datenstrukturen wie Memcache, binäre Suche oder Zufallsbäume für den letzten Schritt der Datensuche verwenden.
Schritte zur Implementierung von konsistentem Hashing
Nachdem Sie die zugrundeliegende Technik erklärt haben, können Sie mit der Implementierung einer konsistenten Hashing-Lösung beginnen, wobei Sie Folgendes beachten sollten
Wie viele Server werden Sie in Ihrer Lösung haben? Erwarten Sie, dass diese Zahl wachsen wird?
Wie werden Sie Server-IDs zuweisen?
Welche Hash-Funktion werden Sie zur Erstellung Ihres Datenhashes verwenden? Sie sollten eine Funktion wählen, die eine einheitliche Ausgabe erzeugt, damit sich Ihre Daten nicht auf einem einzigen Server häufen, sondern gleichmäßig über alle Server verteilt sind.
Überlegen Sie, was passiert, wenn Sie einen Server zu Ihrer Lösung hinzufügen oder entfernen. Sie sollten versuchen, die Server-IDs so gleichmäßig wie möglich zu verteilen, um eine Häufung Ihrer Daten zu vermeiden.
Beispiel für eine konsistente Hashing-Implementierung
Betrachten wir ein Beispiel, bei dem Dateien auf einem von 5 Servern gespeichert werden. Wir werden Server-IDs zwischen 1 und 360 zuweisen.
Die Server sind in einem konzeptionellen Ring angeordnet und erhalten die IDs 74, 139, 220, 310 und 340.
Wir müssen eine neue Datei speichern, wir hacken den Schlüssel dieser Datei, und das Ergebnis ist 1551
Wir führen 1551 MOD 360 durch, was uns 111 ergibt.
Die Datendatei wird also auf dem Server mit der ID 139 gespeichert.

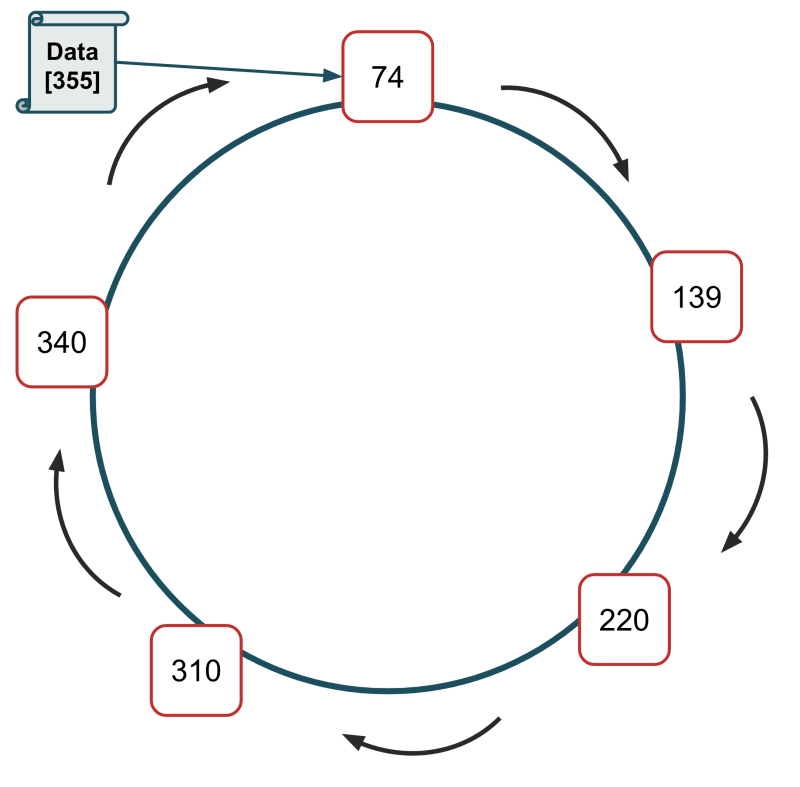
Um ein anderes Beispiel zu betrachten:
Die Server sind in einem konzeptionellen Ring angeordnet und erhalten die IDs 74, 139, 220, 310 und 340
Wir müssen eine neue Datei speichern, wir hacken den Schlüssel dieser Datei, und das Ergebnis ist 1075
Wir führen 1075 MOD 360 durch, was uns 355 ergibt.
Keine Server-ID ist größer als 355; daher wird die Datendatei auf dem Server mit der ID 74 gespeichert.
Konsistente Hashing-Optimierung
Wenn ein Knoten (Server) in einem System mit konsistentem Hashing ausfällt, werden alle Daten dem nächsten Server im Ring neu zugewiesen. Das bedeutet, dass ein ausgefallener Server die Last auf dem nächsten Server verdoppelt, was im besten Fall Ressourcen auf dem überlasteten Server verschwendet und im schlimmsten Fall einen Kaskadenausfall verursachen kann.Eine gleichmäßigere Umverteilung beim Ausfall eines Servers kann dadurch erreicht werden, dass jeder Server einen Hash an mehrere Stellen oder Replikate im Ring sendet. Wenn ein Server beispielsweise vier mögliche Hashes hat und somit an vier Stellen im Ring vorhanden ist, werden die auf diesem Server gespeicherten Daten beim Ausfall dieses Servers an vier verschiedene Stellen umverteilt, so dass die Last auf einem anderen Server nicht mehr als ein zusätzliches Viertel beträgt, was besser zu handhaben ist.
Konsistente Hashing-Implementierung mit PubNub
PubNub ist eine API-Plattform für Entwickler, die es Anwendungen ermöglicht, Nachrichten in großem, globalem Maßstab zu übermitteln. PubNub verfügt über mehrere Präsenzpunkte, die es ermöglichen, Nachrichten sicher, zuverlässig und schnell zu übermitteln.
Um die Skalierbarkeit und Zuverlässigkeit zu gewährleisten, die unsere Kunden erwarten, verwenden wir in unserem Backend verschiedene Techniken, darunter konsistentes Hashing.
Wenn Sie eine Anwendung erstellen, die Daten zwischen Clients oder zwischen einem Client und einem Server in großem Umfang*austauschen muss, **dann müssen Sie sich wahrscheinlich viel mehr Gedanken machen als nur darüber, welcher Hashing-Mechanismus verwendet werden soll*. Überlassen Sie PubNub alle Ihre Kommunikationsanforderungen, damit Sie sich auf Ihre Geschäftslogik konzentrieren können und sich nicht um die Low-Level-Datenübertragung Ihrer Anwendung kümmern müssen, wenn diese skaliert.
Wenn Sie sich für Edge Computing interessieren, sehen Sie sich unsere Edge Message Bus Lösung an, oder erkunden Sie, wie PubNub Kommunikations- und Blockchain Web3 Lösungen unterstützen kann.
PubNub kann kostenlos getestet werden. Melden Sie sich einfach an oder registrieren Sie sich für ein kostenloses Konto, um eine App zu erstellen oder unsere Tour zu erleben, um zu sehen, worum es bei PubNub geht.


















