
This blog post was written for Twilio and originally published on the Twilio blog.
Can AI help me run a faster marathon?
Problem: I play a lot of tennis and run, bike, and walk as my forms of transit, so I have never trained for a half marathon or 10k. However, I KNOW I must train to run a marathon. As a developer, I turned to code, wondering how AI could help me run a faster marathon.
Solution: Read on to learn how to build a personal marathon training plan generator Streamlit-hosted app from personal workout data using the Strava API, LangChain agents, chains, few-shot prompt templating, PromptTemplates, OpenAI, and SendGrid. This can also be applied to personal training, nutrition, and more!
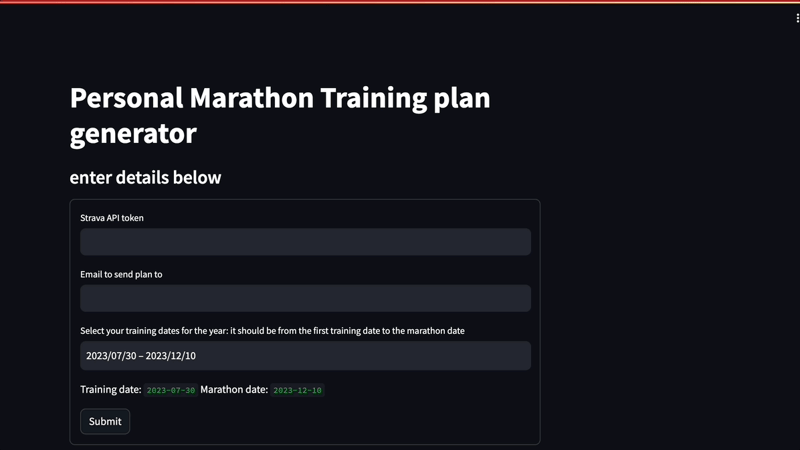
In the Streamlit page above, a user inputs their Strava API token so the app can access their workout data, the date they want to begin training, and the marathon (or race) day. When they click Submit, a custom training plan is generated.
You can test the app out here using a Strava API token generated by following the directions under Strava Activity Webhook Authentication in this tutorial on querying data with LangChain agents.
Do you prefer learning via video more? Check out this TikTok relating to this tutorial--massive thank you to Twilio Community Engagement Manager Sandra Mendez for spearheading this video.
Understanding LangChain Agents
This meaty app uses many features of LangChain, such as agents: agents use LLMs to decide what actions should be taken and they have access to tools like web search or calculators which can be packaged into a logical loop of operations.
For more background on LangChain, you can read this blog post here.
Prerequisites
- A free SendGrid account
- Python installed - download Python here
- An email address to test out this project
- OpenAI Account – make an OpenAI Account here
- A Strava account - sign up for a Strava account if you don't have one already
- A Strava app and API key - follow directions here under Setup the Strava API
- A Strava Auth token - follow directions here under Strava Activity Webhook Authentication You need a Strava app and API key–following the directions above will provide you with the necessary Strava Client Secret in order to generate a Strava Access Token to make a request to access your Strava data. Different Strava API app values include:
- Client ID: Your application ID
- Client Secret: Your client secret (please keep this confidential)
- Authorization/Access token: Your Strava API app's authorization token will need to be regenerated every six hours (should be confidential) Next, after making an OpenAI account if you don't have one already, you can get an OpenAI API Key here by clicking on + Create new secret key. Then, grab a SendGrid API key here.
The Python application will need to have access to these keys, so in your root directory (called strava-langchain) make a .env file to store the API keys safely. The application we create will be able to import this key as an environment variable soon.
In the .env file add the following lines of text, making sure to replace <YOUR-OPENAI-API-KEY> and <YOUR-SENDGRID-KEY> with your actual keys. STRAVA_CLIENT_SECRET should have been used above to generate a Strava Access Token:
OPENAI_API_KEY= <YOUR-OPENAI-KEY>
SENDGRID_API_KEY = <YOUR-SENDGRID-KEY>
STRAVA_CLIENT_SECRET= <YOUR-STRAVA-CLIENT-SECRET>
Your Strava Access Token will be placed into a Streamlit form. Streamlit is an open-source Python app framework that helps developers quickly create web apps for data science and machine learning.
In the root directory run the following commands to install the project's required libraries after making a virtual environment:
python3 -m venv venv
source venv/bin/activate
Make a requirements.txt file containing the following:
chromadb==0.4.5
google-search-results==2.4.2
langchain==0.0.261
numpy==1.25.0
openai==0.27.2
pandas==2.0.3
python-dotenv==1.0.0
PyYAML==6.0
reportlab==4.0.4
Requests==2.31.0
sendgrid==6.10.0
streamlit==1.25.0
tabulate==0.9.0
urllib3==2.0.4
Install them on the command line by running pip install -r requirements.txt.
Then run mkdir data_files to make a folder called data_files to store the activity data.
We will import these in our code soon.
Few-shot prompting Examples
There are a few ways one could go about making an AI personal marathon trainer, workout trainer, or recommendation system. My college classmate-turned Redis AI engineer Sam Partee suggested using few-shot prompting, in which a few explicit examples (or "shots") guide the Large Language Model (LLM) to respond in a certain way.
Create a file named stapp.py and include some examples of marathon training plans. I used OpenAI to create these plans and then formatted them a bit because most marathon plans I found online were not copy-and-pasteable.
examples = [
{
"training_start_date" : "July 19",
"marathon_date" : "November 8",
"pd_run_output": "The average distance is 3.71 miles and the maximum distance is 9.52 miles. The average moving time is not available and the maximum moving time is not available. Other running statistics include total elevation gain, with an average of 47.6 and a maximum of 200.6.",
"num_workouts": "112",
"plan":
"""
Week 1:
Day 1, {training_start_date}: Cross-training - Swim
Day 2: Easy run - 4 miles at an easy pace
Day 3: Cross-training - Elliptical
Day 4: Medium run - 5 miles at a medium pace
...
{marathon_date}: Marathon Day!
Note: The above plan assumes that the student is currently able to comfortably run 4 miles at an easy pace. Adjustments may need
to be made if the student is not yet at this level. Additionally, the plan includes cross-training and rest days to
ensure proper recovery and prevent injury.
"""
}
]
The complete code for that file is here on GitHub. Now let's make some custom tools to help LangChain suggest personalized workouts.
Make Custom Tools to assist LangChain Agents
Using agents allows LLMs access to tools with which LLMs can search the web, do math, run code, and more. Though LLMs are powerful, they still have trouble with certain tasks–that's why you may sometimes need to make custom tools.
LangChain offers a large selection of pre-built tools, but only so many problems can be solved using existing tools.
Create a file named request.py and include the following import statements.
import re
from datetime import date, datetime
import os
import base64
from typing import List, Union
import pandas as pd # dataframe
from reportlab.platypus import SimpleDocTemplate, Paragraph
from reportlab.lib.pagesizes import letter
from reportlab.lib.styles import getSampleStyleSheet
from reportlab.lib.units import inch
import requests
import urllib3
from dotenv import dotenv_values
import streamlit as st
from langchain import LLMChain, LLMMathChain
from langchain.agents import Tool, AgentExecutor, LLMSingleActionAgent, AgentOutputParser, create_pandas_dataframe_agent, initialize_agent, AgentType
from langchain.chat_models import ChatOpenAI
from langchain.llms import OpenAI # , GPT4All
from langchain.prompts import BaseChatPromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import AgentAction, AgentFinish, HumanMessage
from sendgrid import SendGridAPIClient
from sendgrid.helpers.mail import (
Mail, Attachment, FileContent, FileName, FileType, Disposition)
import stapp # file
urllib3.disable_warnings(
urllib3.exceptions.InsecureRequestWarning
)
config = dotenv_values(".env")
Next, we set some variables such as the Strava URL to retrieve a user's Activity data, have the app access its API keys, and then chain LLMs together: the llm variable passes the desired gpt-4-32k model to use with ChatOpenAI and sets the temperature to 0.2–play around with this value. A higher temperature value means the LLM output will include more randomness. Lastly, pass LLM to a math chain to perform complex math problems.
activities_url = "https://www.strava.com/api/v3/athlete/activities"
os.environ["OPENAI_API_KEY"] = config.get('OPENAI_API_KEY')
os.environ["SENDGRID_API_KEY"] = config.get('SENDGRID_API_KEY')
llm = ChatOpenAI(model_name='gpt-4-32k', temperature=0.2)
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
Now make some functions for the custom tools to help the LLM convert meters to miles, calculate the number of days between two dates, and get the number of days in a Pandas dataframe object.
def convert_to_miles(num):
return ((num/m_conv_factor)*1000)/1000.0
def calc_days_btwn(training_start_date, marathon_date):
training_start_date = training_start_date.split(',')[1].strip()
training_start_date = datetime.strptime(training_start_date, '%Y-%m-%d')
training_start_date = datetime.date(training_start_date)
delta = marathon_date - training_start_date
return delta.days-1
#number of workouts in Strava data
def num_rows_in_dataframe(df):
return len(df.index)
Beneath that, add a helper function to help validate user emails.
email_regex = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,7}\b'
def validate_email(email):
# pass the regular expression and the string into the fullmatch() method
if(re.fullmatch(email_regex, email)):
return True
else:
return False
It's time to make a Custom Prompt Template in LangChain to make constructing prompts using dynamic inputs easier.
Make Custom Prompt Template
LangChain provides a set of default prompt templates to generate prompts for different tasks. However, for some projects like this one, developers might want to create a prompt template with specific dynamic instructions for the LLM–in instances like that, you can create a custom prompt template similar to the one below right inside request.py beneath validate_email:
#Set up a prompt template
class CustomPromptTemplate(BaseChatPromptTemplate):
template: str
# The list of tools available
tools: List[Tool]
def format_messages(self, **kwargs) -> str:
# Get the intermediate steps (AgentAction, Observation tuples)
# Format them in a particular way
intermediate_steps = kwargs.pop("intermediate_steps")
thoughts = ""
for action, observation in intermediate_steps:
thoughts += action.log
thoughts += f"\nObservation: {observation}\nThought: "
# Set the agent_scratchpad variable to that value
kwargs["agent_scratchpad"] = thoughts
# Create a tools variable from the list of tools provided
kwargs["tools"] = "\n".join([f"{tool.name}: {tool.description}" for tool in self.tools])
# Create a list of tool names for the tools provided
kwargs["tool_names"] = ", ".join([tool.name for tool in self.tools])
formatted = self.template.format(**kwargs)
return [HumanMessage(content=formatted)]
class CustomOutputParser(AgentOutputParser):
def parse(self, llm_output: str) -> Union[AgentAction, AgentFinish]:
# Check if agent should finish
if "Marathon Day" in llm_output:
return AgentFinish(
return_values={"output": llm_output.split("Marathon Day:")[-1].strip()},
log=llm_output,
)
elif marathon_date in llm_output:
return AgentFinish(
# Return values is generally always a dictionary with a single `output` key
# It is not recommended to try anything else at the moment :)
return_values={"output": llm_output.split(marathon_date)[-1].strip()},
log=llm_output,
)
# Parse out the action and action input
regex = r"Action\s*\d*\s*:(.*?)\nAction\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)"
match = re.search(regex, llm_output, re.DOTALL)
if not match:
try:
action = match.group(1).strip()
action_input = match.group(2)
# Return the action and action input
return AgentAction(tool=action, tool_input=action_input.strip(" ").strip('"'), log=llm_output)
except ValueError as e:
response = str(e)
if not response.startswith("Could not parse LLM output: `"):
raise e
response = response.removeprefix("Could not parse LLM output: `").removesuffix("`")
That helps shape the output. Let's work on receiving the input.
Make a Streamlit web app in Python
To make a webpage to receive input about the user for their personal marathon training plan, we will use Streamlit.
In request.py, we set a title, subheader, the dates that are first displayed when the date input widget is rendered, and a Streamlit form containing two text_input fields for the user's Strava token and email, make the date input widget, and then write the input dates to the page and split up the input dates into two variables. This code goes directly beneath response = response.removeprefix("Could not parse LLM output: ").removesuffix("").
st.title('Personal Marathon Training plan generator')
st.subheader('enter details below')
today = datetime.now()
jul_30 = date(today.year, 7, 30)
dec_31 = date(today.year, 12, 31)
with st.form('my_form'):
strava_token_input = st.text_input('Strava API token')
email = st.text_input('Email to send plan to')
dates = st.date_input(
"Select your training dates for the year: it should be from the first training date to the marathon date",
(jul_30, date(today.year, 12, 10)),
jul_30,
dec_31
)
st.write('Training date: ', dates[0], "Marathon date: ", dates[1])
training_start_date = dates[0]
marathon_date = dates[1]
submitted = st.form_submit_button('Submit')
Run the command streamlit run request.py in your terminal. An application should open up on your localhost:8080:
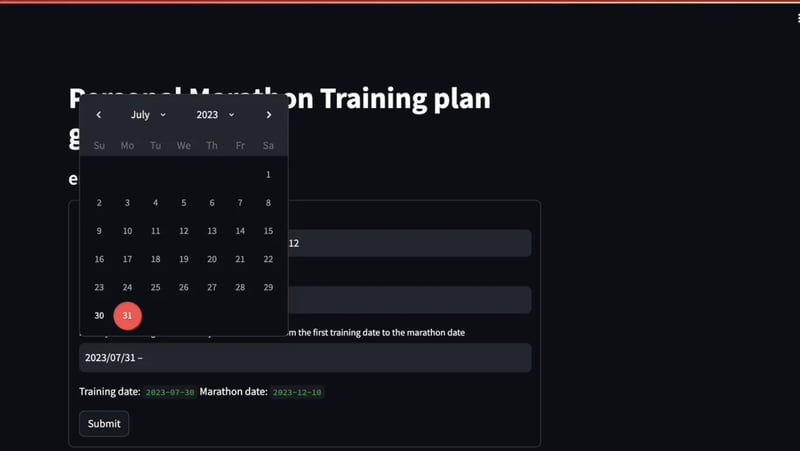
Beneath the last line marathon_date = dates[1], add the following code to validate the user input:
if submitted:
if not validate_email(email):
st.error("invalid email", icon="🚨")
st.cache_data()
VALIDANSWERS = False
elif training_start_date > marathon_date:
st.error("Start date must be earlier than end date", icon="🚨")
st.cache_data()
VALIDANSWERS = False
try:
r = requests.get('https://www.strava.com/api/v3/activities?access_token=' + strava_token_input)
r.raise_for_status()
VALIDANSWERS = True
except requests.exceptions.HTTPError as e:
print(e)
st.error("Check Strava token")
st.cache_data()
VALIDANSWERS = False
if VALIDANSWERS:
Get Strava data into Pandas and CSV form
The parameters and headers need to be set in order to call a Strava API request. my_dataset contains data from just the first page of user activities, so to retrieve more activity data, loop through four pages of Strava activities and add them to my_dataset before calling pd.json_normalize on it to turn the semi-structured JSON data into a flat table to work with it.
Directly beneath the if VALIDANSWERS: line, add the following code:
header = {'Authorization': 'Bearer ' + strava_token_input}
params = {'per_page': 200, 'page': 1} #max 200 per page, can only do 1 page at a time
my_dataset = requests.get(activities_url, headers=header, params=params).json() #activities 1st page
page = 0
for x in range(1,5): #loop through 4 pages of strava activities
page +=1
params = {'per_page': 200, 'page': page}
my_dataset += requests.get(activities_url, headers=header, params=params).json()
activities = pd.json_normalize(my_dataset)
Next, create a new Pandas Dataframe object with specific columns containing the categories you want to consider: this tutorial is only looking at the activity name, type (bike ride, run, swim, tennis, etc), distance, moving time, total elevation gain, and start date.
The following code goes beneath activities = pd.json_normalize(my_dataset) and creates a CSV file of the activities data after removing items from 2021 so it only includes workouts from 2022 and 2023. You can replace this with another year! It then makes a CSV file named data_files/runs.csv containing the runs and no other activity types.
cols = ['name', 'type', 'distance', 'moving_time', 'total_elevation_gain', 'start_date']
activities = activities[cols]
activities = activities[activities["start_date"].str.contains("YEAR-YOU-WANT-TO-IGNORE-WORKOUTS") == False]
activities.to_csv('data_files/activities.csv', index=False)
runs = activities.loc[activities['type'] == 'Run']
runs.to_csv('data_files/runs.csv', index=False)
Now, convert meters to miles and the moving time seconds to minutes and hours with the code below:
data_run_df = pd.read_csv('data_files/runs.csv')
data_activity_df = pd.read_csv('data_files/activities.csv')
m_conv_factor = 1609
data_run_df['distance'] = data_run_df['distance'].map(lambda x: convert_to_miles(x))
data_activity_df['distance'] = data_activity_df['distance'].map(lambda x: convert_to_miles(x))
#convert moving time secs to mins, hours
data_run_df['moving_time'] = data_run_df['moving_time'].astype(str).map(lambda x: x[7:]) #slices off 0 days from moving_time
data_run_df.to_csv('data_files/runs.csv')
data_activity_df = pd.read_csv('data_files/activities.csv')
Next, this data will be passed to a LangChain agent.
Generate a Personal Marathon Plan with LangChain Agents
In the same request.py file, make an array called tools containing the tools the agent has access to. Each tool gets a name, function to run, and description. The description is optional, but recommended because it's used by an agent to determine tool use.
Beneath creating the data_activity_df variable, add the tools array:
tools = [
Tool(
name = "rows in csv",
func = lambda df: num_rows_in_dataframe(df),
description="use to get the number of rows in csv file to calculate averages from running data"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
),
Tool(
name="days_between",
func=lambda day1, day2=marathon_date: calc_days_btwn(day1, day2),
description="useful for when you need to calculate the number of days between two dates of type date, like between the training start date and the marathon date"
)
]
Now, create some Pandas dataframe agents to interact with the Strava data. These agents are similar to CSV agents which load data from CSV files instead of dataframes and perform queries. You could use both and see how the output differs.
Agents can be chained together to build more complex applications. Another agent used below is of type ZERO_SHOT_REACT_DESCRIPTION. Zero-shot means the agent functions only on the present action — it lacks memory. It uses the ReAct framework to decide which tool to use, solely based on the tool’s description.
The code runs the agents, telling them what to do and saving the output to variables for use later. Be specific with the prompts here and play around with different questions or commands.
Beneath the tools array, add:
pd_agent_run = create_pandas_dataframe_agent(OpenAI(temperature=0.3), data_run_df, verbose=True)
pd_agent_activity = create_pandas_dataframe_agent(OpenAI(temperature=0.3), data_activity_df, verbose=True)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
num_workouts = agent.run(f'Calculate the number of days between these two dates representing the number of workouts in the plan: {marathon_date} and {training_start_date}. You have access to tools')
pd_run_output = pd_agent_run.run("Calculate average distance and maximum distance in miles and average moving time and maximum moving time in minutes. Additionally, calculate any other running statistics from the data you think would be helpful to consider in marathon training.")
Next, make a prompt template, a "reproducible way to generate a prompt" containing a text string ("the template"). It accepts a set of parameters from the user and generates a prompt. This mirrors the items in stapp.py's examples array.
prefix contains directions and context to the LLM and suffix is the user input and output indicator. Finally, these, along with the input variables which are unique to the student the plan is being made for, are passed into FewShotPromptTemplate.
coach_template = """training_start_date:{training_start_date}, marathon_date:{marathon_date}, pd_run_output: {pd_run_output}, num_workouts: {num_workouts}, plan: {plan}
"""
example_prompt = PromptTemplate(input_variables=["training_start_date", "marathon_date", "pd_run_output", "num_workouts", "plan"], template=coach_template)
prefix = """
You are a marathon trainer tasked with crafting one personalized marathon training plan containing according to your student's previous runs and activities.
For each week you should recommend 2 cross-training activities and no more than one run greater than 14 miles per week. The longest run you recommend should be 20 miles around 2 weeks before {marathon_date}.
There should be {num_workouts} workouts for {num_workouts} days, and there should be easy workouts and rest days in the week leading up to {marathon_date}.
Slightly modify the following example marathon training plans based on your student and the days beginning on {training_start_date} up until {marathon_date} to create one personalized training plan with each workout on a new line:
"""
suffix = """
training_start_date: {training_start_date}, marathon_date: {marathon_date}, pd_run_output: {pd_run_output}, num_workouts: {num_workouts}
"""
few_shot_prompt_template = FewShotPromptTemplate(
examples=stapp.examples,
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
input_variables=["marathon_date", "training_start_date", "pd_run_output", "num_workouts"]
)
Create a custom output parser object to help structure the response from the LLM and LLM chain, the most common type of chain. The LLM chain consists of the model and prompt. For this case it's an LLM but it could be a ChatModel. The LLM is passed to a LLMSingleActionAgent to complete a single action and structure the response from the LLM.
This agent is passed to an AgentExecutor. An executor differs from an agent in that it is a running instance of an agent used to execute tasks according to the agent’s decisions and configured tools. In short, agents decide which tools to use and the executors execute them. The output of the Executor (which is given the user input) is the personalized marathon training plan. Beneath the FewShotPromptTemplate() function, add the following code:
output_parser = CustomOutputParser()
#LLM chain consisting of the LLM and a prompt
llm_chain = LLMChain(llm=llm, prompt=few_shot_prompt_template)
tool_names = [tool.name for tool in tools]
agent = LLMSingleActionAgent(
llm_chain=llm_chain,
output_parser=output_parser,
stop=["\Marathon Day:"],
allowed_tools=tool_names
)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True)
plan = agent_executor({"marathon_date":marathon_date, "training_start_date": training_start_date, "pd_run_output": pd_run_output, "num_workouts": num_workouts})
print('plan being print ', plan)
Email the Plan as a PDF using Twilio SendGrid
We access the part of the plan containing the dates, replace new lines with breaks because the ReportLab Python library to generate and format PDFs ignores \n, and send an outbound email using Twilio SendGrid–the email body says "good luck at your marathon on {marathon_date}" with the plan attached.
plan = plan['output']
plan = str(plan).replace('\n','<br />') #each workout on new line
message = Mail(
from_email='langchain_sendgrid_marathon_trainer@sf.com',
to_emails=email,
subject='Your AI-generated marathon training plan',
html_content='<strong>Good luck at your marathon on %s</strong>!\n\nYour plan is attached.'%(marathon_date))
The email attachment is formatted and styled using ReportLab. The following code returns a stylesheet with a few basic heading and text styles to format the PDF attachment which is in the form of a SimpleDocTemplate document. The document is built using the Paragraph class that lets us format the text with inline font style (and optional color changes) using an XML style markup.
The encoded file is passed as an attachment to the SendGrid email. If the email is sent successfully, the Streamlit app displays a success message; otherwise, it displays an error message.
styleN = getSampleStyleSheet()['Normal']
story = []
pdf_name = 'plan.pdf'
doc = SimpleDocTemplate(
pdf_name,
pagesize=letter,
bottomMargin=.4 * inch,
topMargin=.6 * inch,
rightMargin=.8 * inch,
leftMargin=.8 * inch)
P = Paragraph(plan, styleN)
story.append(P)
doc.build(
story,
)
with open(pdf_name, 'rb') as f:
data = f.read()
f.close()
encoded_file = base64.b64encode(data).decode()
attachedFile = Attachment(
FileContent(encoded_file),
FileName('personal_ai_generated_marathon_training_plan.pdf'),
FileType('application/pdf'),
Disposition('attachment')
)
message.attachment = attachedFile
sg = SendGridAPIClient()
response = sg.send(message)
if response.status_code == 202:
st.success("Email sent! Check your email for your personal training plan")
print(f"Response Code: {response.status_code} \n Message sent!")
else:
st.warning("Email not sent--check email")
Run streamlit run request.py in your terminal. Fill in your information (like Strava Access Token, the email where you want to receive the generated plan, the training start date, and marathon race date!) on the Streamlit app, click Submit, and wait for your personal marathon training plan in your email.
If the Submit button is clicked, we check the input (dates and email). If the inputs are either:
- invalid: the Streamlit app displays an error message and caches the function so the user can try valid input.
- valid: the Streamlit app displays a success message and it's time to use the user's Strava API token to get their Strava workout data.
Play around with different agents, prompting, and different parameters like temperature (which affects the risks the agent takes and creativity of the output).
The complete code above can be found here on GitHub.
What's Next for Agents and SendGrid
So will I use this to train for my marathon? I haven't coded this much since college (or had this much fun doing so) and this was a great way to learn many of LangChain's features, but time will tell –work travel, tennis practices, and AI hackathons make consistent training difficult. I do want to continue trying different ways of changing the output--this is a lot of code which I feel like could be unnecessary, but it yielded the best results.
There's so much developers can do with communication APIs and AI–this is just the tip of the iceberg. You can use a different LLM, look at different Strava data, try different agents (or use chains instead!), embeddings, use LLaMA 2 or other similar models on Replicate, and more. You could use SMS or Twilio Conversations to collect user input instead of Streamlit, or make the LLM recommend other workouts for different goals or meals based on nutrition data!
Let me know online what you're building (and send running tips!)
- Twitter: @lizziepika
- GitHub: elizabethsiegle
- Email: lsiegle@twilio.com


















