
This blog post was written for Twilio and originally published on the Twilio blog.
Pose detection is one fun and interesting task in computer vision and machine learning. In a video chat, it could be used to detect if someone is touching their face, falling asleep, performing a yoga pose correctly, and so much more!
Read on to learn how to perform pose detection in the browser of a Twilio Video chat application using TensorFlow.js and the PoseNet model.

Setup
To build a Twilio Programmable Video application, we will need:
- A Twilio account - sign up for a free one here and receive an extra $10 if you upgrade through this link
- Account SID: find it in your account console here
- API Key SID and API Key Secret: generate them here
- The Twilio CLI
Follow this post to get setup with a starter Twilio Video app and to understand Twilio Video for JavaScript a bit more, or download this repo and follow the README instructions to get started.
In assets/video.html, import TensorFlow.js and the PoseNet library on lines 8 and 9 in-between the
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/posenet"></script>
Then in the same file add a canvas element with in-line styling above the video tag, and edit the video tag to have relative position.
<canvas id="canvas" style="position:absolute;top:0;left:0;z-index:1;"></canvas>
<video id="video" autoplay muted="true" position="relative" width="320" height="240"></video>
Now it's time to write some TensorFlow.js code!
Pose Detection
In assets/index.js, beneath const video = document.getElementById("video"); add the following lines:
const canvas = document.getElementById("canvas");
const ctx = canvas.getContext("2d");
const minConfidence = 0.2;
const VIDEO_WIDTH = 320;
const VIDEO_HEIGHT = 240;
const frameRate = 20;
With that code we grab our canvas HTML element and its 2D rendering context, set the minimum confidence level, video width, video height, and frame rate. In machine learning, confidence means the probability of the event (in this case, getting the poses the model is confident it is predicting from the video). The frame rate is how often our canvas will redraw the poses detected.
After the closing brackets and parentheses for navigator.mediaDevices.getUserMedia following localStream = vid;, make this method estimateMultiplePoses to load the PoseNet model (it runs all in the browser so no pose data ever leaves a user’s computer) and estimate poses for one person.
const estimateMultiplePoses = () => {
posenet
.load()
.then(function (net) {
console.log("estimateMultiplePoses .... ");
return net.estimatePoses(video, {
decodingMethod: "single-person",
});
})
.then(function (poses) {
console.log(`got Poses ${JSON.stringify(poses)}`);
});
};
PoseNet for TensorFlow.js can estimate either one pose or multiple poses. This means it has one version of the algorithm that detects just one person in an image or video, as well as another version of the algorithm that detects multiple people in an image or video. This project uses the single-person pose detector as it is faster and simpler, and for a video chat there's probably only one person on the screen. Call estimateMultiplePoses by adding the following code beneath localStream = vid;:
const intervalID = setInterval(async () => {
try {
estimateMultiplePoses();
} catch (err) {
clearInterval(intervalID);
setErrorMessage(err.message);
}
}, Math.round(1000 / frameRate));
return () => clearInterval(intervalID);
Now run twilio serverless:deploy on your command line and visit the assets/video.html URL under Assets. Open your browser’s developer tools where the poses detected are being printed to the console:

Nice! Poses are being detected.
Each pose object contains a list of keypoints and a confidence score determining how accurate the estimated keypoint position is, ranging from 0.0 and 1.0. Developers can use the confidence score to hide a pose if the model is not confident enough.
Now, let's draw those keypoints on the HTML canvas over the video.
Draw Segments and Points on the Poses
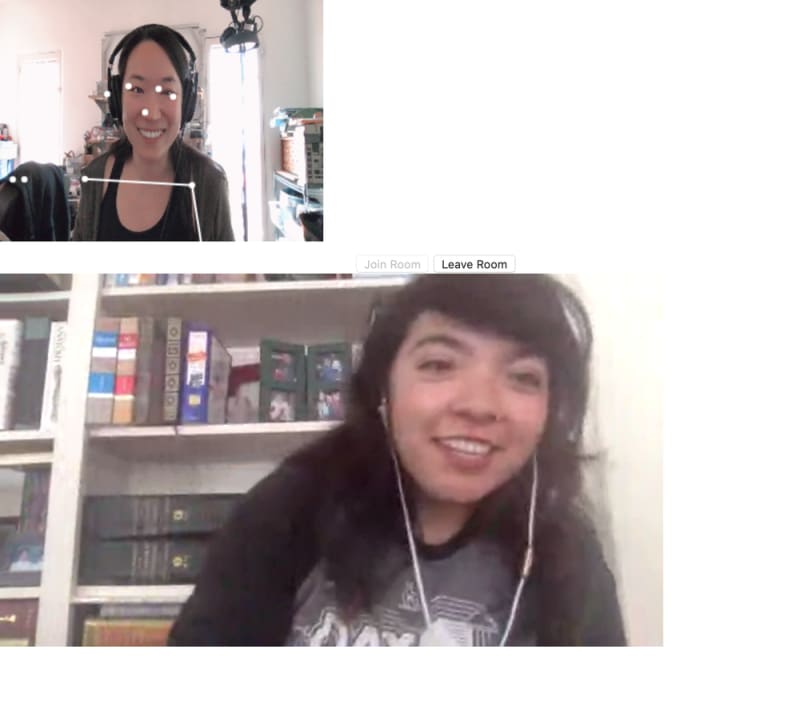
Right beneath the last code you wrote, make a drawPoint function. The function takes in three parameters and draws a dot centered at (x, y) with a radius of size r over detected joints on the HTML canvas.
function drawPoint(y, x, r) {
ctx.beginPath();
ctx.arc(x, y, r, 0, 2 * Math.PI);
ctx.fillStyle = "#FFFFFF";
ctx.fill();
}
Then, given keypoints like the array returned from PoseNet, loop through those given points, extract their (x, y) coordinates, and call the drawPoint function.
function drawKeypoints(keypoints) {
for (let i = 0; i < keypoints.length; i++) {
const keypoint = keypoints[i];
console.log(`keypoint in drawkeypoints ${keypoint}`);
const { y, x } = keypoint.position;
drawPoint(y, x, 3);
}
}
Next, make a helper function drawSegment that draws a line between two given points:
function drawSegment(
pair1,
pair2,
color,
scale
) {
ctx.beginPath();
ctx.moveTo(pair1.x * scale, pair1.y * scale);
ctx.lineTo(pair2.x * scale, pair2.y * scale);
ctx.lineWidth = 2;
ctx.strokeStyle = color;
ctx.stroke();
}
That drawSegment helper function is called in drawSkeleton to draw the lines between related points in the keypoints array returned by the PoseNet model:
function drawSkeleton(keypoints) {
const color = "#FFFFFF";
const adjacentKeyPoints = posenet.getAdjacentKeyPoints(
keypoints,
minConfidence
);
adjacentKeyPoints.forEach((keypoint) => {
drawSegment(
keypoint[0].position,
keypoint[1].position,
color,
1,
);
});
}
To estimateMultiplePoses, add this code that loops through the poses returned from the TensorFlow.js PoseNet model. For each pose, it sets and restores the canvas, and calls drawKeypoints and drawSkeleton if the model is confident enough in its prediction of the detected poses:
const estimateMultiplePoses = () => {
posenet
.load()
.then(function (net) {
console.log("estimateMultiplePoses .... ");
return net.estimatePoses(video, {
decodingMethod: "single-person",
});
})
.then(function (poses) {
console.log(`got Poses ${JSON.stringify(poses)}`);
canvas.width = VIDEO_WIDTH;
canvas.height = VIDEO_HEIGHT;
ctx.clearRect(0, 0, VIDEO_WIDTH, VIDEO_HEIGHT);
ctx.save();
ctx.drawImage(video, 0, 0, VIDEO_WIDTH, VIDEO_HEIGHT);
ctx.restore();
poses.forEach(({ score, keypoints }) => {
if (score >= minConfidence) {
drawKeypoints(keypoints);
drawSkeleton(keypoints);
}
});
});
Your complete index.js file should look like this:
(() => {
'use strict';
const TWILIO_DOMAIN = location.host;
const ROOM_NAME = 'tf';
const Video = Twilio.Video;
let videoRoom, localStream;
const video = document.getElementById("video");
const canvas = document.getElementById("canvas");
const ctx = canvas.getContext("2d");
const minConfidence = 0.2;
const VIDEO_WIDTH = 320;
const VIDEO_HEIGHT = 240;
const frameRate = 20;
// preview screen
navigator.mediaDevices.getUserMedia({ video: true, audio: true })
.then(vid => {
video.srcObject = vid;
localStream = vid;
const intervalID = setInterval(async () => {
try {
estimateMultiplePoses();
} catch (err) {
clearInterval(intervalID)
setErrorMessage(err.message)
}
}, Math.round(1000 / frameRate))
return () => clearInterval(intervalID)
});
function drawPoint(y, x, r) {
ctx.beginPath();
ctx.arc(x, y, r, 0, 2 * Math.PI);
ctx.fillStyle = "#FFFFFF";
ctx.fill();
}
function drawKeypoints(keypoints) {
for (let i = 0; i < keypoints.length; i++) {
const keypoint = keypoints[i];
console.log(`keypoint in drawkeypoints ${keypoint}`);
const { y, x } = keypoint.position;
drawPoint(y, x, 3);
}
}
function drawSegment(
pair1,
pair2,
color,
scale
) {
ctx.beginPath();
ctx.moveTo(pair1.x * scale, pair1.y * scale);
ctx.lineTo(pair2.x * scale, pair2.y * scale);
ctx.lineWidth = 2;
ctx.strokeStyle = color;
ctx.stroke();
}
function drawSkeleton(keypoints) {
const color = "#FFFFFF";
const adjacentKeyPoints = posenet.getAdjacentKeyPoints(
keypoints,
minConfidence
);
adjacentKeyPoints.forEach((keypoint) => {
drawSegment(
keypoint[0].position,
keypoint[1].position,
color,
1,
);
});
}
const estimateMultiplePoses = () => {
posenet
.load()
.then(function (net) {
console.log("estimateMultiplePoses .... ");
return net.estimatePoses(video, {
decodingMethod: "single-person",
});
})
.then(function (poses) {
console.log(`got Poses ${JSON.stringify(poses)}`);
canvas.width = VIDEO_WIDTH;
canvas.height = VIDEO_HEIGHT;
ctx.clearRect(0, 0, VIDEO_WIDTH, VIDEO_HEIGHT);
ctx.save();
ctx.drawImage(video, 0, 0, VIDEO_WIDTH, VIDEO_HEIGHT);
ctx.restore();
poses.forEach(({ score, keypoints }) => {
if (score >= minConfidence) {
drawKeypoints(keypoints);
drawSkeleton(keypoints);
}
});
});
};
// buttons
const joinRoomButton = document.getElementById("button-join");
const leaveRoomButton = document.getElementById("button-leave");
var site = `https://${TWILIO_DOMAIN}/video-token`;
console.log(`site ${site}`);
joinRoomButton.onclick = () => {
// get access token
axios.get(`https://${TWILIO_DOMAIN}/video-token`).then(async (body) => {
const token = body.data.token;
console.log(token);
Video.connect(token, { name: ROOM_NAME }).then((room) => {
console.log(`Connected to Room ${room.name}`);
videoRoom = room;
room.participants.forEach(participantConnected);
room.on("participantConnected", participantConnected);
room.on("participantDisconnected", participantDisconnected);
room.once("disconnected", (error) =>
room.participants.forEach(participantDisconnected)
);
joinRoomButton.disabled = true;
leaveRoomButton.disabled = false;
});
});
};
leaveRoomButton.onclick = () => {
videoRoom.disconnect();
console.log(`Disconnected from Room ${videoRoom.name}`);
joinRoomButton.disabled = false;
leaveRoomButton.disabled = true;
};
})();
const participantConnected = (participant) => {
console.log(`Participant ${participant.identity} connected'`);
const div = document.createElement('div');
div.id = participant.sid;
participant.on('trackSubscribed', track => trackSubscribed(div, track));
participant.on('trackUnsubscribed', trackUnsubscribed);
participant.tracks.forEach(publication => {
if (publication.isSubscribed) {
trackSubscribed(div, publication.track);
}
});
document.body.appendChild(div);
//new div
}
const participantDisconnected = (participant) => {
console.log(`Participant ${participant.identity} disconnected.`);
document.getElementById(participant.sid).remove();
}
const trackSubscribed = (div, track) => {
div.appendChild(track.attach());
}
const trackUnsubscribed = (track) => {
track.detach().forEach(element => element.remove());
}
On the command line, run twilio serverless:deploy, visit the assets/video.html URL under Assets and see your poses detected in the browser in a Twilio Video application using TensorFlow.js.

Share it with friends and you have your own fun video chat room with pose detection using TensorFlow.js! You can find the completed code here on GitHub.
What's next after building pose detection in Programmable Video?
Performing pose detection in a video app with TensorFlow.js is just the beginning. You can use this as a stepping stone to build games like motion-controlled fruit ninja, check a participant's yoga pose or tennis hitting form, put masks on faces, and more. Let me know what you're building in the comments below or online.
- Twitter: @lizziepika
- GitHub: elizabethsiegle
- email: lsiegle@twilio.com


















